
sql 부하 테스트 프로그램 c#
카테고리 없음 / 2024. 12. 12. 16:14

|
메시지 4326, 수준 16, 상태 1, 줄 237
이 백업 세트의 로그는 LSN 363000000085600001에서 종료되는데 데이터베이스에 적용하기에는 너무 이릅니다. LSN 363000000090400001을(를) 포함하는 최신 로그 백업이 복원될 수 있습니다.
메시지 3013, 수준 16, 상태 1, 줄 237
RESTORE LOG이(가) 비정상적으로 종료됩니다.
이 백업보다 더 *뒤*에 백업한 로그를 리스토어 한다.
2시 백업본이면, 3시 백업본을 리스토어 해봐라~
로그 백업이 restore 되기위해서는 LSN이 순서대로 연결 되어야한다.
$dbServerIpOrDomain = 'domain'
$dbServerPort = '1433'
$dbName = 'master'
$dbServerAccountId = 'id'
$dbServerAccountPass = 'pass'
$query =
@"
select @@servername Servername , @@version Version
;
"@
function SqlQuery
{
param (
[parameter(Mandatory=$true)] [string] $server,
[parameter(Mandatory=$true)] [string] $port,
[parameter(Mandatory=$true)] [string] $database,
[parameter(Mandatory=$true)] [string] $id,
[parameter(Mandatory=$true)] [string] $pass,
[parameter(Mandatory=$true)] [string] $query,
[parameter(Mandatory=$false)] [switch] $isRead = $false ,
[parameter(Mandatory=$false)] [int] $queryTimeout = 0 ,
[parameter(Mandatory=$false)] [int] $connTimeout = 5 ,
[parameter(Mandatory=$false)] [string] $appName = "PowerShell"
)
try
{
$substringLen = 100
if ($query.Length -lt $substringLen)
{
$substringLen = $query.Length
}
$querySubstring = $query.substring(0, $substringLen)
$conn = New-Object System.Data.SQLClient.SQLConnection
$conn.ConnectionString = "server=$($server),$($port);database=$($database);User Id=$($id);Password=$($pass);Connect Timeout=$($connTimeout);Application Name=$($appName)"
$conn.Open()
$cmd = New-Object System.Data.SQLClient.SQLCommand
$cmd.Connection = $conn
$cmd.CommandText = $query
$cmd.CommandTimeout=$queryTimeout
if($isRead)
{
$ds=New-Object system.Data.DataSet
$da=New-Object system.Data.SqlClient.SqlDataAdapter($cmd)
$da.fill($ds) | Out-Null
Write-Host ($ds.Tables | Format-Table | Out-String)
}
else
{
$cmd.ExecuteNonQuery() | Out-Null
}
$conn.Close()
Write-Host "SUCCESS, SERVER : $($server), QUERY : $($querySubstring) ..."
}
catch
{
Write-Host "FAILED, SERVER : $($server), QUERY : $($querySubstring) ..."
throw "FAILED SERVER : $($server), ERROR MESSAGE : $($_)"
}
}
Clear
ipconfig /all
Resolve-DnsName $dbServerIpOrDomain
Test-NetConnection $dbServerIpOrDomain -Port $dbServerPort
SqlQuery -server $dbServerIpOrDomain -port $dbServerPort -database $dbName -id $dbServerAccountId -pass $dbServerAccountPass -query $query -isRead:$true# DNS 를 조회하면 2개의 ip와 TTL 1200 이 출력된다.
Resolve-DnsName lissql1
#PS C:\Users\dba> Resolve-DnsName lissql1
#Name Type TTL Section IPAddress
#---- ---- --- ------- ---------
#lissql1.foo.company.local A 1200 Answer 100.107.61.251
#lissql1.foo.company.local A 1200 Answer 100.107.62.51
# 모듈을 불러들인다.
Import-Module FailoverClusters
# Network Name 을 찾는다.
Get-ClusterResource -Cluster avconsole-clu1
# agsql1_lissql1 Network Name을 대상으로 아래 설정을 수행한다.
Get-ClusterResource -Cluster avconsole-clu1 -Name "agsql1_lissql1" | Get-ClusterParameter
Get-ClusterResource -Cluster avconsole-clu1 -Name "agsql1_lissql1" | Set-ClusterParameter -Name RegisterAllProvidersIP 0
Get-ClusterResource -Cluster avconsole-clu1 -Name "agsql1_lissql1" | Set-ClusterParameter -Name HostRecordTTL 30
# 리소스 재시작과 클러스터 시작을 해줘야 적용된다.
Stop-ClusterResource -Cluster avconsole-clu1 -Name "agsql1_lissql1"
Start-ClusterResource -Cluster avconsole-clu1 -Name "agsql1_lissql1"
Start-Clustergroup -Cluster avconsole-clu1 -Name "agsql1"
# 최종 확인, 아래처럼 1개의 ip와 ttl 30초로 설정 되어야 한다.
Resolve-DnsName lissql1
#PS C:\Users\dba> Resolve-DnsName lissql1
#
#Name Type TTL Section IPAddress
#---- ---- --- ------- ---------
#lissql1.foo.company.local A 30 Answer 100.107.61.251
# AG 에서 failover 해본다. (30초 기다려보고 Resolve-DnsName lissql1 응답을 확인한다.)
AD DNS 서버에서 아래값을 셋팅 한다. 기본값은 180초
***************************************************************
Set-DnsServerDsSetting -PollingInterval 30
Get-DnsServerDsSetting
-- 테이블 스위치를 이용한 일반 컬럼에 identity 속성 추가
if object_id('t_product') is not null
drop table t_product
go
if object_id('t_product_identity') is not null
drop table t_product_identity
go
-- int 컬럼
create table t_product
( idx int not null
, shopid int
, productid int
, contentOtherCol char(400)
)
go
-- PK 인덱스를 추가한다.
alter table t_product add constraint PK_t_product primary key (idx)
go
with temp as
(
select
top 2000000 cast(row_number() over (order by (select 1)) as int) idx
, cast('contents other column' as char(400)) contentOtherCol
from sys.objects a1
cross join sys.objects a2
cross join sys.objects a3
cross join sys.objects a4
cross join sys.objects a5
)
insert into t_product (idx, shopid, productid, contentOtherCol)
select
idx
, cast(abs(checksum(newid())) % 2 as int) shopid
, cast(abs(checksum(newid())) % 100000 as int) productid
, contentOtherCol
--into t_product
from temp
go
-- 교체할 테이블 생성 identity 가 있는 테이블
create table t_product_identity
( idx int identity(1,1) not null
, shopid int
, productid int
, contentOtherCol char(400)
)
go
alter table t_product_identity add constraint PK_t_product_identity primary key (idx)
go
-- identity 없는 테이블과 idneitty 있는 테이블의 스키마를 바꿔치기 한다.
alter table t_product switch to t_product_identity
go
-- 테이블 삭제
drop table t_product
go
-- 이름 변경
exec sp_rename 't_product_identity','t_product'
go
-- 인덱스 이름 변경
exec sp_rename 't_product.PK_t_product_identity', 'PK_t_product';
go
select top 10 * from t_product
go
-- 0 으로 출력됨
select IDENT_CURRENT( 't_product' )
go
-- modify identity value
declare @max int
select @max=max(idx) from t_product
if @max IS NULL --check when max is returned as null
SET @max = 0
select @max
DBCC CHECKIDENT ('t_product', RESEED, @max)
go
-- 현재 max 값으로 셋팅 확인
select IDENT_CURRENT( 't_product' )
go
-- 이름 확인
exec sp_helpindex t_product
go
-- identity 속성 확인
exec sp_help t_product
goPK 가 없는 경우 PK 가 있는 경우에 따라 시간이 얼마나 차이나고, 가장 빠른 변환 방법은 무엇인가 고민해보자
-- identity, pk, int nonclustered index -> identity, pk bigint 로 변경시간 테스트
if object_id('t_product') is not null
drop table t_product
go
-- 재현을 위해서 int identity 컬럼을 만든다.
create table t_product
( idx int identity(1,1)
, shopid int
, productid int
, contentOtherCol char(400)
)
go
-- PK 인덱스를 추가한다.
alter table t_product add constraint PK_t_product primary key (idx)
go
-- identity 테이블 입력 가능하게
set identity_insert t_product on
go
-- identity 있는 상태로 데이터를 생성해 넣는다.
with temp as
(
select
top 2000000 cast(row_number() over (order by (select 1)) as int) idx
, cast('contents other column' as char(400)) contentOtherCol
from sys.objects a1
cross join sys.objects a2
cross join sys.objects a3
cross join sys.objects a4
cross join sys.objects a5
)
insert into t_product (idx, shopid, productid, contentOtherCol)
select
idx
, cast(abs(checksum(newid())) % 2 as int) shopid
, cast(abs(checksum(newid())) % 100000 as int) productid
, contentOtherCol
--into t_product
from temp
go
-- identity 기능을 활성화 한다.
set identity_insert t_product off
go
----------------------------------------------
-- 일반적인 방법으로 실행
-- 점검시간 X*2 = 9초
----------------------------------------------
-- 0초
alter table t_product drop constraint PK_t_product
go
-- 4초 전체 리빌드
ALTER TABLE t_product ALTER COLUMN idx bigint not null
go
-- 5초 전체 리빌드
alter table t_product add constraint PK_t_product primary key (idx)
go
----------------------------------------------
-- 테이블 압축과 online 옵션 이용
-- 점검시간 X*1 = 3초
----------------------------------------------
-- 테스트로 압축 해본다. (압축 시간은 얼마나 걸리나? online = 7초, offline = 1초, 테이블 사이즈와 비즈니스 영향도에 따라 선택)
-- 압축은 언제든지 stop 하면 취소된다. online, offline 구분없음
-- *** 운영시간에 테이블을 압축 해둔다.
ALTER TABLE DBO.t_product REBUILD PARTITION = ALL
WITH (DATA_COMPRESSION = PAGE, ONLINE = ON);
go
--ALTER TABLE DBO.t_product REBUILD PARTITION = ALL
--WITH (DATA_COMPRESSION = PAGE);
--go
--sp_help t_product
-- pk 가 있으면, int 에서 bigint 로 바로 변경이 불가능하기에 pk 를 삭제한다.
-- ALTER TABLE t_product ALTER COLUMN idx bigint not null -- 에러
-- 메시지 5074, 수준 16, 상태 1, 줄 57
-- The object 'PK_t_product' is dependent on column 'idx'.
-- 메시지 4922, 수준 16, 상태 9, 줄 57
-- ALTER TABLE ALTER COLUMN idx failed because one or more objects access this column.
-- pk 삭제 0초
alter table t_product drop constraint PK_t_product
go
--insert into t_product (
--shopid
--, productid
--, contentOtherCol
--)
--values (
--1
--, 1
--, 1
--)
--select IDENT_CURRENT( 't_product' )
-- 3~4배 느려짐
-- ALTER TABLE t_product ALTER COLUMN idx bigint not null with (online = on)
-- int 에서 bigint 로 변경한다. (압축테이블 : 메타 변경 0초 (online offline 0초) VS. 비 압축테이블 : 테이블 전체 리빌드 2초, 온라인 : 7초)
-- * 반드시 압축해서 사용한다 0초 아니면 시간이 오래걸림
ALTER TABLE t_product ALTER COLUMN idx bigint not null
go
-- pk 를 다시 만들어 준다. (offline : 3초, online : 8초, 언제든지 취소 가능하다.)
-- pk 를 이용하는 쿼리가 있는지 확인하고 없다면 online 옵션 사용
-- pk 를 사용하는 쿼리가 있으면 점검 시간에 offline 으로 사용
-- *** 점검 시간의 대부분 사용함
alter table t_product add constraint PK_t_product primary key (idx)
alter table t_product add constraint PK_t_product primary key (idx) with (online = on)
--exec sp_help t_product
--exec sp_helpindex t_product
--select IDENT_CURRENT( 't_product' )
-- 언제든지 online 으로 풀 수 있음, query stop 언제든지 가능
ALTER TABLE DBO.t_product REBUILD PARTITION = ALL
WITH (DATA_COMPRESSION = NONE, ONLINE = ON);
go
----------------------------------------------
-- pk 가 없는 일반테이블의 경우, 테이블 압축을 이용하면 int -> bigint 변경은 0초
-- 운영 정지시간 X*0 = 0초
----------------------------------------------
if object_id('t_product') is not null
drop table t_product
go
-- 재현을 위해서 int identity 컬럼을 만든다.
create table t_product
( idx int identity(1,1)
, shopid int
, productid int
, contentOtherCol char(400)
)
go
-- identity 테이블 입력 가능하게
set identity_insert t_product on
go
-- identity 있는 상태로 데이터를 생성해 넣는다.
with temp as
(
select
top 2000000 cast(row_number() over (order by (select 1)) as int) idx
, cast('contents other column' as char(400)) contentOtherCol
from sys.objects a1
cross join sys.objects a2
cross join sys.objects a3
cross join sys.objects a4
cross join sys.objects a5
)
insert into t_product (idx, shopid, productid, contentOtherCol)
select
idx
, cast(abs(checksum(newid())) % 2 as int) shopid
, cast(abs(checksum(newid())) % 100000 as int) productid
, contentOtherCol
--into t_product
from temp
go
-- identity 기능을 활성화 한다.
set identity_insert t_product off
go
-- 테스트로 압축 해본다. (압축 시간은 얼마나 걸리나? online = 7초, offline = 1초, 테이블 사이즈와 비즈니스 영향도에 따라 선택)
-- 압축은 언제든지 stop 하면 취소된다. online, offline 구분없음
-- *** 운영시간에 테이블을 압축 해둔다.
ALTER TABLE DBO.t_product REBUILD PARTITION = ALL
WITH (DATA_COMPRESSION = PAGE, ONLINE = ON);
go
--ALTER TABLE DBO.t_product REBUILD PARTITION = ALL
--WITH (DATA_COMPRESSION = PAGE);
--go
-- 3~4배 느려짐
-- ALTER TABLE t_product ALTER COLUMN idx bigint not null with (online = on)
-- int 에서 bigint 로 변경한다. (압축테이블 : 메타 변경 0초 (online offline 0초) VS. 비 압축테이블 : 테이블 전체 리빌드 2초, 온라인 : 7초)
-- * 반드시 압축해서 사용한다 0초 아니면 시간이 오래걸림
ALTER TABLE t_product ALTER COLUMN idx bigint not null
go
--exec sp_help t_product
--exec sp_helpindex t_product
--select IDENT_CURRENT( 't_product' )
-- 언제든지 online 으로 풀 수 있음, query stop 언제든지 가능
ALTER TABLE DBO.t_product REBUILD PARTITION = ALL
WITH (DATA_COMPRESSION = NONE, ONLINE = ON);
gounique index를 string에 주고 싶다.
그럼 code table에 허용하는 범위가 아니므로 collation을 지원하는 collation으로 바꾸어 준다.
쉽게 이야기 하면 a 와 A 를 구분 못하는 korean_wansung_ci_as와 같은 이슈이다.
DROP TABLE IF EXISTS dbo.unicode_string_test
CREATE TABLE dbo.unicode_string_test (
string NVARCHAR(10)
)
-- 1 : U+0031
-- 2 : U+0032
-- ー : U+30FC
-- ヽ : U+30FD
INSERT dbo.unicode_string_test SELECT N'111'
INSERT dbo.unicode_string_test SELECT N'11ー'
INSERT dbo.unicode_string_test SELECT N'11ヽ'
INSERT dbo.unicode_string_test SELECT N'1ーー'
INSERT dbo.unicode_string_test SELECT N'1ヽヽ'
INSERT dbo.unicode_string_test SELECT N'ーーー'
INSERT dbo.unicode_string_test SELECT N'222'
INSERT dbo.unicode_string_test SELECT N'22ー'
INSERT dbo.unicode_string_test SELECT N'22ヽ'
INSERT dbo.unicode_string_test SELECT N'2ーー'
INSERT dbo.unicode_string_test SELECT N'2ヽヽ'
INSERT dbo.unicode_string_test SELECT N'ヽヽヽ'
SELECT * FROM dbo.unicode_string_test WHERE string = N'111'
SELECT * FROM dbo.unicode_string_test WHERE string = N'11ー'
SELECT * FROM dbo.unicode_string_test WHERE string = N'1ーー'
SELECT * FROM dbo.unicode_string_test WHERE string = N'1ーヽ'
SELECT * FROM dbo.unicode_string_test WHERE string = N'ーーー'
SELECT * FROM dbo.unicode_string_test WHERE string = N'222'
SELECT * FROM dbo.unicode_string_test WHERE string = N'22ヽ'
SELECT * FROM dbo.unicode_string_test WHERE string = N'2ヽヽ'
SELECT * FROM dbo.unicode_string_test WHERE string = N'2ーヽ'
SELECT * FROM dbo.unicode_string_test WHERE string = N'ヽヽヽ'
go
alter table unicode_string_test
alter column string NVARCHAR(10) COLLATE Korean_Wansung_BIN2
go
create unique nonclustered index nc_unicode_string_test on unicode_string_test (string)
go
select * from dbo.unicode_string_test where string = N'111'
go
SELECT name, description FROM sys.fn_helpcollations() where name like '%korea%'
SELECT * FROM dbo.unicode_string_test where string = N'111' collate Korean_Wansung_BIN2
go
SERVER
<powershell 을 관리자모드로 시작>
PS> cd "C:\Program Files\Microsoft SQL Server\150\Setup Bootstrap\SQL2019"
PS> .\Setup /QUIET /ACTION=REBUILDDATABASE /INSTANCENAME=MSSQLSERVER /SQLSYSADMINACCOUNTS=USERDOMAIN\userAccount /SAPWD=!1P@ssw0rd /SQLCOLLATION=SQL_Latin1_General_CP1_CI_AS
DATABASE or TABLE
Set or change the database collation - SQL Server
Set or change the database collation
learn.microsoft.com
-- 각 지점의 위도 경도 구하기 (아래 사이트에서 구함, kakao api 이용해도 가능)
-- https://tablog.neocities.org/keywordposition
-- 검색한 위도 경도를 이용해 서울역에서 용인두산위브까지의 거리 SQL서버로 구하기
-- Parse 는 대소문자를 구분하고, STGeomFromText 에서 SRID를 4236으로 고정한 값으로 계산함
-- https://learn.microsoft.com/en-us/sql/t-sql/spatial-geography/parse-geography-data-type?view=sql-server-ver16
-- https://learn.microsoft.com/ko-kr/sql/t-sql/spatial-geometry/stgeomfromtext-geometry-data-type?view=sql-server-ver16
-- POINT는 점으로 계산, LINESTRING 은 선분으로 계산 WKT 표현임, 모든 데이터베이스에 이런거 다 지원함
DECLARE @g geography;
DECLARE @h geography;
SET @g = geography::Parse('POINT(126.9720686318752 37.55593878839654)');
SET @h = geography::Parse('POINT(127.15001085373893 37.28340610861977)');
SELECT @g.STDistance(@h); --this is the distance in meters
GO
DECLARE @g geography;
DECLARE @h geography;
SET @g = geography::STGeomFromText('POINT(126.9720686318752 37.55593878839654)', 4326);
SET @h = geography::STGeomFromText('POINT(127.15001085373893 37.28340610861977)', 4326);
SELECT @g.STDistance(@h); --this is the distance in meters
GO
-- SET @g = geography::STGeomFromText('LINESTRING(-122.360 47.656, -122.343 47.656)', 4326);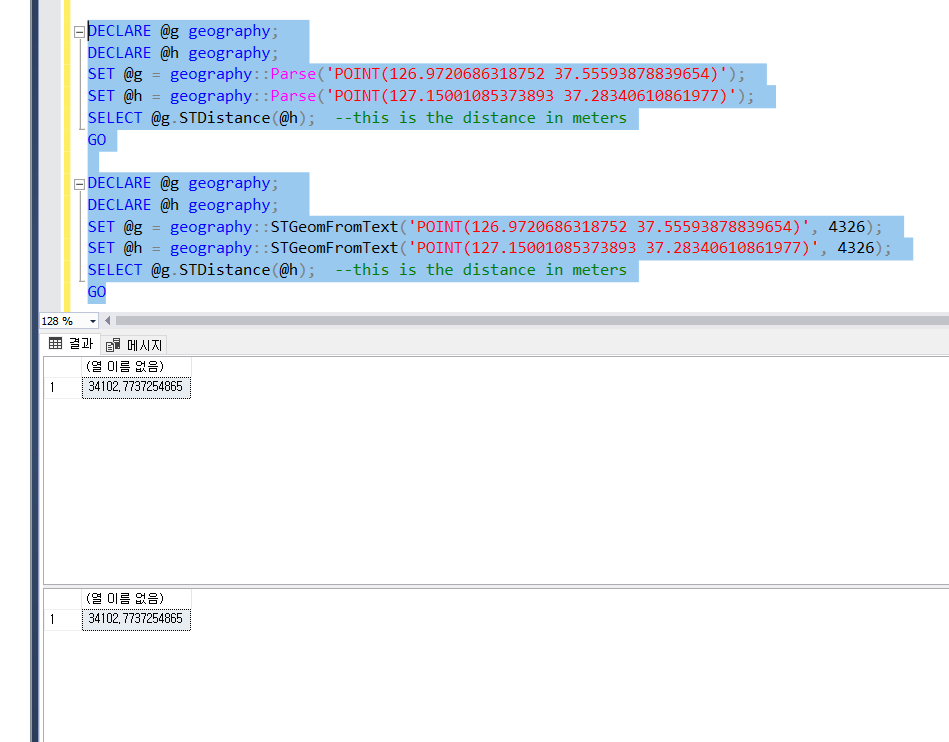
Troubleshoot performance issues with narrow and wide plans in SQL Server - SQL Server
Provides information to understand and troubleshoot update statements that use wide or narrow plans.
learn.microsoft.com
SELECT
@@servername servername
, SERVERPROPERTY('Edition') as edition
, cpu_count / hyperthread_ratio AS sockets
, hyperthread_ratio AS logical_cores_per_socket
, cpu_count AS total_logical_cpu_count
, @@version version
, CONVERT (varchar(256), SERVERPROPERTY('collation')) collation
FROM sys.dm_os_sys_info;
go
select * from sys.dm_os_sys_info;
select *
from sysprocesses a
cross apply
(
select * from sys.dm_exec_sql_text(a.sql_handle)
) b
where spid > 50 and kpid <> 0 and spid <> @@spid and loginame <> 'lazylog'
go
SELECT
cpu_idle = record.value('(./Record/SchedulerMonitorEvent/SystemHealth/SystemIdle)[1]', 'int'),
cpu_sql = record.value('(./Record/SchedulerMonitorEvent/SystemHealth/ProcessUtilization)[1]', 'int')
FROM (
SELECT TOP 1 CONVERT(XML, record) AS record
FROM sys.dm_os_ring_buffers
WHERE ring_buffer_type = N'RING_BUFFER_SCHEDULER_MONITOR'
AND record LIKE '% %'
ORDER BY TIMESTAMP DESC
) as cpu_usage
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
SELECT '01' OrderKey,'OS_MEMORY_TOTAL' MemType, physical_memory_kb PagesKB FROM SYS.DM_OS_SYS_INFO
UNION ALL
SELECT '02' OrderKey,'SQL_VISIBLE_TARGET_KB' MemType, visible_target_kb PagesKB FROM SYS.DM_OS_SYS_INFO
UNION ALL
SELECT '03' OrderKey,'SQL_COMMITTED_KB' MemType, committed_kb PagesKB FROM SYS.DM_OS_SYS_INFO
UNION ALL
SELECT '04' OrderKey,'OS_MEMORY_CLERKS_TOTAL' MemType, SUM(pages_kb) + sum(virtual_memory_committed_kb)+sum(awe_allocated_kb)+sum(shared_memory_committed_kb) PagesKB FROM SYS.DM_OS_MEMORY_CLERKS
UNION ALL
SELECT *
FROM
(
SELECT TOP 20 '04' OrderKey, type MemType, SUM(pages_kb) +sum(virtual_memory_committed_kb)+sum(awe_allocated_kb)+sum(shared_memory_committed_kb) PagesKB FROM SYS.DM_OS_MEMORY_CLERKS
GROUP BY TYPE
ORDER BY 3 DESC
) A
ORDER BY 1,3 DESC