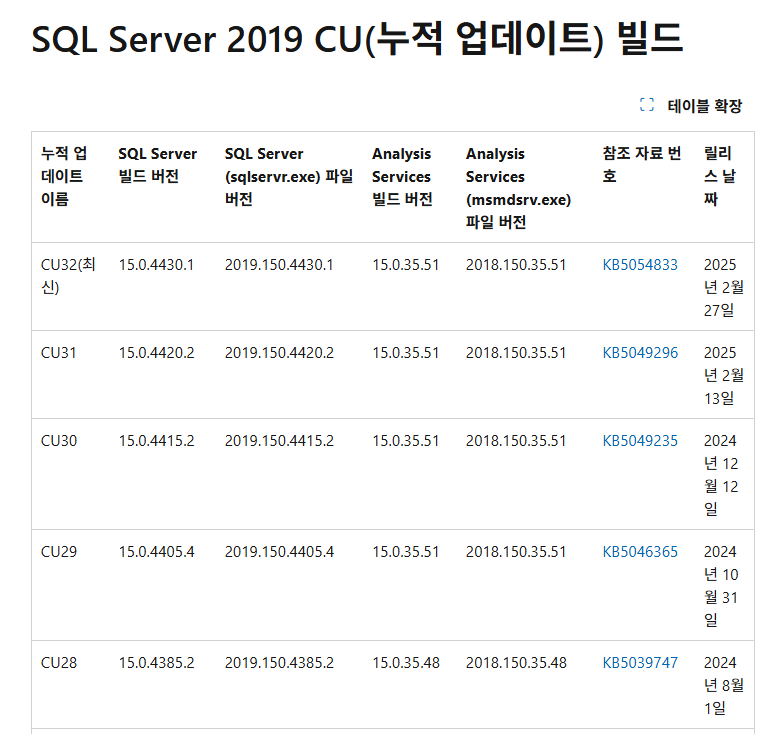
예전에는 CU (누적 업데이트 라인), GDR (보안 업데이트 라인) 이렇게 2개만 있었다. 지금도 여전히 GDR 라인만 적용해 보안 업데이트만 할 수 있고, CU가 한번이라도 적용된 서버에는 순수 GDR을 설치할 수 없다. (GDR 최상위 버전도 항상 CU 버전보다 낮았다.) 그러나, MU 정책을 바꾸면서, CU+GDR이 나오고 있다. MS 업데이트 버그로 인해 고생을 좀 해보고 나니, CU+GDR 로 한개 정도 오래된 버전을 설치하는게 가장 좋은 정책이지 않을까 생각한다. (너무 최신버전을 적용하면 벤더도 자기네 버그인지 모르니 분석에 오래 걸린다.)
멀티부팅 환경이라면, 암호를 알고 있는 OS로 부팅해 관리자 모드 cmd로 부팅 뒤 아래 두 개의 실행파일을 바꿔두면, 다음 부팅 화면에서 접근성 메뉴(utilman.exe)나 shift 5번 연타(sethc.exe)를 하면, OS계정의 암호를 변경하거나 Administrator 계정을 활성화 암호를 변경할 수 있다. 멀티 부팅이 아니면 윈도우 설치 USB를 만들어 같은 작업을 할 수 있다.
삽질 여담으로, utilman.exe의 경우 cmd 창이 바로 닫히는 경우가 있더라, sethc.exe로 shift 5연타는 잘 동작함. 그리고 cmd 창이 오류가 있다고 보이는데, 실행이 다 되더라 그냥 빠르게 닫히는 거더라. 그냥 sethc.exe를 이용하는게 좋고 둘 다 바꾸어 하는게 좋다. 그리고, 바로 shift 리부팅으로는 들어가 터미널 열려고 하면, 다시 암호를 물어보더라(그래서 암호를 알고있는 멀티부팅 서버로 들어가 터미널을 열고 암호를 모르는 서버의 파일을 바꿔치기 함)....그러니, 터미널로 들어갈 방법이 없더라. 윈도우 설치용 USB가 있는게 가장 좋고, 나는 운좋게 멀티 부팅 환경이라 따로 설치 usb 만들지 않고 성공했다. (암호를 계속 바꾸라 하니....기억이 안난다...ㅋ)
update(insert update delete merge 모두를 그냥 update 라 한다)에서 narrow 와 wide 플랜을 선택할 때 traceflag를 이용하지 말고 top 절과 optimize for 를 이용하는 방법도 있다.
-- All qualifying rows will be deleted
DECLARE @Rows bigint = 9223372036854775807;
-- Optimize the plan for deleting 100 rows
DELETE TOP (@Rows)
FROM dbo.[Data]
OUTPUT
Deleted.RowID,
Deleted.SomeValue,
Deleted.StartDate,
Deleted.CurrentFlag
WHERE StartDate = CONVERT(date, '20140106', 112)
OPTION (OPTIMIZE FOR (@Rows = 100));
CTE 를 쓰면 어떤 잇점이 있을까?
쿼리 가독성과 대상의 확인 select 가 하나의 쿼리로 할 수 있다. (select 만 실행 가능하다. )
옵티마이저가 이상한 플랜 만들수 있으니 성능 테스트 해보고 쓰자~
WITH
LastRowPerDay AS
(
SELECT
D.CurrentFlag
FROM dbo.[Data] AS D
WHERE
D.RowID =
(
SELECT MAX(D2.RowID)
FROM dbo.[Data] AS D2
WHERE D2.StartDate = D.StartDate
)
)
UPDATE LastRowPerDay
SET CurrentFlag = 'true';
-- VS
UPDATE D
SET CurrentFlag = 'true'
FROM dbo.[Data] AS D
WHERE D.RowID = (
SELECT MAX(D2.RowID)
FROM dbo.[Data] AS D2
WHERE D2.StartDate = D.StartDate
);
An Unexpected Side-Effect of Adding a Filtered Index
Adding a filtered index can have surprising side-effects on existing queries, even where it seems the new filtered index is completely unrelated. This post looks at an example affectingDELETEstatements that results in poor performance and anincreased risk of deadlock.
Note:The behaviour described in this article is current as of November 2024. (tested on SQL Server 2022 CU15)
Test Environment
The following table will be used throughout this post:
CREATE TABLE dbo.[Data]
(
RowID integer IDENTITY NOT NULL,
CONSTRAINT PK_Data_RowID
PRIMARY KEY CLUSTERED (RowID),
SomeValue integer NOT NULL,
StartDate date NOT NULL,
CurrentFlag bit NOT NULL,
Padding char(50) NOT NULL
DEFAULT REPLICATE('ABCDE', 10)
);
This next statement creates 499,999 rows of sample data:
INSERT dbo.[Data]
WITH (TABLOCKX)
(
SomeValue,
StartDate,
CurrentFlag
)
SELECT
SomeValue = CONVERT(integer, RAND(n) * 1e6) % 1000,
StartDate = DATEADD(DAY, (N.n - 1) % 31, CONVERT(date, '20140101', 112)),
CurrentFlag = CONVERT(bit, 0)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n < 500 * 1000;
That uses a Numbers table as a source of consecutive integers from 1 to 499,999. In case you do not have one of those in your test environment, the following code can be used to efficiently create one containing integers from 1 to 1,000,000:
WITH
N1 AS (SELECT N1.n FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS N1 (n)),
N2 AS (SELECT L.n FROM N1 AS L CROSS JOIN N1 AS R),
N3 AS (SELECT L.n FROM N2 AS L CROSS JOIN N2 AS R),
N4 AS (SELECT L.n FROM N3 AS L CROSS JOIN N2 AS R),
N AS (SELECT ROW_NUMBER() OVER (ORDER BY n) AS n FROM N4)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM N
OPTION (MAXDOP 1);
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1);
The basis of the later tests will be to delete rows from the test table for a particular StartDate. To make the process of identifying rows to delete more efficient, add this nonclustered index:
CREATE NONCLUSTERED INDEX
IX_Data_StartDate
ON dbo.[Data]
(StartDate);
The sample data
Once those steps are completed, the data will look like this:
SELECT TOP (100)
D.RowID,
D.SomeValue,
D.StartDate,
D.CurrentFlag,
D.Padding
FROM dbo.[Data] AS D
ORDER BY
D.RowID;
The SomeValue column data may be slightly different due to the pseudo-random generation, but this difference is not important. Overall, the sample data contains 16,129 rows for each of the 31 StartDate dates in January 2014:
SELECT
D.StartDate,
NumRows = COUNT_BIG(*)
FROM dbo.[Data] AS D
GROUP BY
D.StartDate
ORDER BY
D.StartDate;
The last step we need to perform to make the data somewhat realistic, is to set the CurrentFlag column to true for the highest RowID for each StartDate. The following script accomplishes this task:
WITH
LastRowPerDay AS
(
SELECT
D.CurrentFlag
FROM dbo.[Data] AS D
WHERE
D.RowID =
(
SELECT MAX(D2.RowID)
FROM dbo.[Data] AS D2
WHERE D2.StartDate = D.StartDate
)
)
UPDATE LastRowPerDay
SET CurrentFlag = 'true';
The execution plan for this update features aSegment-Top combinationto efficiently locate the highest RowID per day:
Notice how the execution plan bears little resemblance to the written form of the query. This is a great example of how the optimizer works from the logical SQL specification, rather than implementing the SQL directly. In case you are wondering, the Eager Table Spool in that plan is required forHalloween Protection.
Deleting a Day of Data
With the preliminaries completed, the task at hand is to delete rows for a particular StartDate. This is the sort of query you might routinely run on the earliest date in a table, where the data has reached the end of its useful life.
Taking 1 January 2014 as our example, the test delete query is simple:
DELETE FROM
dbo.[Data]
WHERE
1 = 1
AND StartDate = CONVERT(date, '20140101', 112);
The execution plan is likewise pretty simple, though worth looking at in a bit of detail:
Note:If you don’t see a separate Index Delete operator, try changing the maximum memory available to SQL Server to around 4GB. You may then need to repopulate the test table or clear the plan cache to get the desired plan shape.
Plan analysis
The Index Seek on the far right uses the nonclustered index to find rows for the specified StartDate value. It returns just the RowID values it finds, as the operator tooltip confirms:
If you are wondering how the StartDate index manages to return the RowID, remember that RowID is the unique clustered index for the table, so it is automatically included in the StartDate nonclustered index.
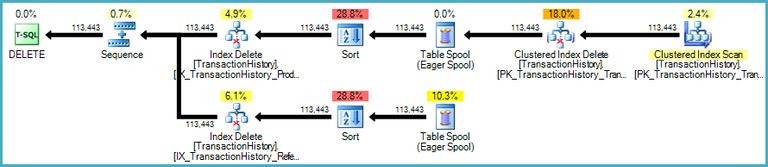
The next operator in the plan is the Clustered Index Delete. This uses the RowID value found by the Index Seek to locate rows to remove.
The final operator is an Index Delete. This removes rows from the nonclustered indexIX_Data_StartDatethat are related to the RowID removed by the Clustered Index Delete. To locate these rows in the nonclustered index, the query processor needs the StartDate (the key for the nonclustered index).
Remember the original Index Seek did not return the Start Date, just the RowID. So how does the query processor get the StartDate for the index delete? In this particular case, the optimizer might have noticed that the StartDate value is a constant and optimized it away, but this is not what happened. The answer is that the Clustered Index Delete operatorreadsthe StartDate value for the current row and adds it to the stream. Compare the Output List of the Clustered Index Delete shown below, with that of the Index Seek just above:
It might seem surprising to see a Delete operatorreadingdata, but this is the way it works. The query processor knows it will have to locate the row in the clustered index in order to delete it, so it might as well defer reading columns needed to maintain nonclustered indexes until that time, if it can.
Adding a Filtered Index
Now imagine someone has a crucial query against this table that is performing badly. The helpful DBA performs an analysis and adds the following filtered index:
CREATE NONCLUSTERED INDEX
FIX_Data_SomeValue_CurrentFlag
ON dbo.[Data]
(SomeValue)
INCLUDE
(CurrentFlag)
WHERE
CurrentFlag = 'true';
The new filtered index has the desired effect on the problematic query and everyone is happy. Notice that the new index does not reference the StartDate column at all, so we do not expect it to affect our day-delete query at all.
Deleting a day with the filtered index in place
We can test that expectation by deleting data for a second time:
DELETE FROM
dbo.[Data]
WHERE
1 = 1
AND StartDate = CONVERT(date, '20140102', 112);
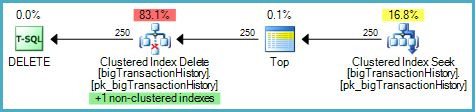
Suddenly, the execution plan has changed to a parallel Clustered Index Scan:
If you don’t see a parallel plan, ensure your cost threshold for parallelism is set to the default value of 5 for these tests.
Notice there is no separate Index Delete operator for the new filtered index. The optimizer has chosen to maintain this index inside the Clustered Index Delete operator. This is highlighted inPlan Exploreras shown above (“+1 non-clustered indexes”) with full details in the tooltip:
If the table is large, this change to a parallel scan might be very significant. What happened to the nice Index Seek on StartDate, and why did a completely unrelated filtered index change things so dramatically?
Finding the problem
The first clue comes from looking at the properties of the Clustered Index Scan:
As well as finding RowID values for the Clustered Index Delete operator to delete, this operator is now reading CurrentFlag values. The need for this column is unclear, but it does at least begin to explain the decision to scan: The CurrentFlag column is not part of our StartDate nonclustered index.
We can confirm this by rewriting the delete query to force the use of the StartDate nonclustered index:
DELETE FROM D
FROM dbo.[Data] AS D
WITH (INDEX(IX_Data_StartDate))
WHERE
1 = 1
AND StartDate = CONVERT(date, '20140103', 112);
The execution plan is closer to its original form, but it now features a Key Lookup:
The Key Lookup properties confirm this operator is retrieving CurrentFlag values:
You might also have noticed the warning triangles in the last two plans. These are missing index warnings:
This is further confirmation that SQL Server would like to see the CurrentFlag column included in the nonclustered index. The reason for the change to a parallel Clustered Index Scan is now clear: The query processor decides that scanning the table will be cheaper than performing the Key Lookups.
Yes, but why?
This is all very weird. In the original execution plan, SQL Server was able toreadextra column data needed to maintain nonclustered indexes at the Clustered Index Delete operator. The CurrentFlag column value is needed to maintain the filtered index, so why does SQL Server not just handle it in the same way?
The short answer is that it can, but only If the filtered index is maintained in a separate Index Delete operator. We can force this for the current query usingundocumented trace flag 8790. Without this trace flag, the optimizer chooses whether to maintain each index in a separate operator or as part of the base table operation.
-- Forced wide update plan
DELETE FROM
dbo.[Data]
WHERE
1 = 1
AND StartDate = CONVERT(date, '20140105', 112)
OPTION
(QUERYTRACEON 8790);
The execution plan is back to seeking the StartDate nonclustered index:
The Index Seek returns just RowID values (no CurrentFlag):
The Clustered Index Delete nowreadsthe columns needed to maintain the nonclustered indexes, including CurrentFlag:
This data is eagerly written to a table spool, which is replayed for each index that needs maintaining. Notice also the explicit Filter operator before the Index Delete operator for the filtered index.
Another pattern to watch out for
This problem does not always result in a table scan instead of an index seek. To see an example of this, add another index to the test table:
CREATE NONCLUSTERED INDEX
IX_Data_SomeValue_CurrentFlag
ON dbo.[Data]
(SomeValue, CurrentFlag);
Note this index isnotfiltered, and does not involve the StartDate column. Now try a day-delete query again:
DELETE FROM
dbo.[Data]
WHERE
1 = 1
AND StartDate = CONVERT(date, '20140104', 112);
The optimizer now comes up with this monster:
This query plan has a high surprise factor, but the root cause is the same. The CurrentFlag column is still needed, but now the optimizer chooses an index intersection strategy to get it instead of a table scan. Using the trace flag forces a per-index maintenance plan and sanity is once again restored (the only difference is an extra spool replay to maintain the new index):
Only Filtered Indexes Cause This
This issue only occurs if the optimizer chooses to maintain a filtered index in a Clustered Index Delete operator. Non-filtered indexes are not affected, as the following example shows. The first step is to drop the filtered index:
DROP INDEX
FIX_Data_SomeValue_CurrentFlag
ON dbo.[Data];
Now we need to write the query in a way that convinces the optimizer to maintain all the indexes in the Clustered Index Delete. My choice for this is to use a variable and a hint to lower the optimizer’s row count expectations:
-- All qualifying rows will be deleted
DECLARE @Rows bigint = 9223372036854775807;
-- Optimize the plan for deleting 100 rows
DELETE TOP (@Rows)
FROM dbo.[Data]
OUTPUT
Deleted.RowID,
Deleted.SomeValue,
Deleted.StartDate,
Deleted.CurrentFlag
WHERE StartDate = CONVERT(date, '20140106', 112)
OPTION (OPTIMIZE FOR (@Rows = 100));
The execution plan is:
Both nonclustered indexes are maintained by the Clustered Index Delete:
The Index Seek returns only the RowID:
The columns needed for the index maintenance are retrieved internally by the delete operator. These details are not exposed in show plan output (so the output list of the delete operator would be empty). I added anOUTPUTclause to the query to show the Clustered Index Delete once again returning data it did not receive on its input:
Final Thoughts
This is a tricky limitation to work around. On the one hand, we generally do not want to use undocumented trace flags in production systems.
The natural ‘fix’ is to add the columns needed for filtered index maintenance toallnonclustered indexes that might be used to locate rows to delete. This is not a very appealing proposition, from a number of points of view. Another alternative is to just not use filtered indexes at all, but that is hardly ideal either.
My feeling is that the query optimizer ought to consider a per-index maintenance alternative for filtered indexes automatically, but its reasoning appears to be incomplete in this area right now (and based on simple heuristics rather than properly costing per-index/per-row alternatives).
To put some numbers around that statement, the parallel clustered index scan plan chosen by the optimizer came in at5.5units in my test. The same query with the trace flag estimates a cost of1.4units. With the third index in place, the parallel index-intersection plan chosen by the optimizer had an estimated cost of4.9, whereas the trace flag plan came in at2.7units (all tests on SQL Server 2014 RTM CU1 build 12.0.2342 under the 120 cardinality estimation model and withtrace flag 4199enabled).
I regard this as behaviour that should be improved. You can vote to agree with meon this Azure Feedback item.
Most tuning efforts for data-changing operations concentrate on theSELECTside of the query plan. Sometimes people will also look atstorage engineconsiderations (likelockingortransaction log throughput) that can have dramatic effects. A number of common practices have emerged, such as avoiding large numbers of row locks and lock escalation, splitting large changes into smaller batches of a few thousand rows, and combining a number of small changes into a single transaction in order to optimize log flushes.
This is all good, but what about the data-changing side of the query plan—theINSERT,UPDATE,DELETE, orMERGEoperation itself—are there anyquery processorconsiderations we should take into account? The short answer is yes.
The query optimizer considers different plan options for the write-side of an execution plan, though there isn’t a huge amount of T-SQL language support that allows us to affect these choices directly. Nevertheless, there are things to be aware of, and things we can look to change.
Note: In this post I am going to use the termupdate(lower case) to apply toanyoperation that changes the state of the database (INSERT,UPDATE,DELETE, andMERGEin T-SQL). This is a common practice in the literature, and is used inside SQL Server too as we will see.
The Three Basic Update Forms
Query plans execute using a demand-driven iterator model, and updates are no exception. Parent operators drive child operators (to therightof the parent) to do work by asking them for a row at a time.
DECLARE @T table (ProductID integer NOT NULL);
INSERT @T (ProductID)
SELECT P.ProductID
FROM Production.Product AS P;
Plan execution starts at the far left, where you can think of the green T-SQLINSERTicon as representing rows returned to the client. This root node asks its immediate child operator (theTable Insert) for a row. TheTable Insertrequests a row from theIndex Scan, which provides one. This row is inserted into the heap, and an empty row is returned to the root node (if theINSERTquery contained anOUTPUTclause, the returned row would contain data).
This row-by-row process continues until all source rows have been processed. Notice that the XML showplan output shows the HeapTable Insertis performed by anUpdateoperator internally.
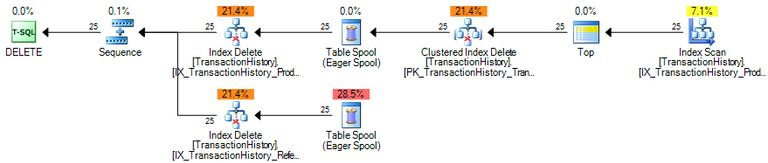
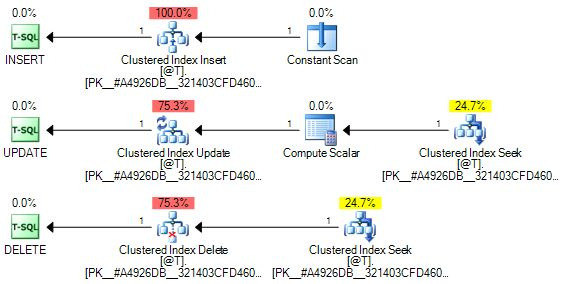
1. Wide, per-index updates
Wide (aka per-index) update plans have a separate update operator for each clustered and nonclustered index.
An example per-index update plan is shown below:
This plan updates the base table using aClustered Index Deleteoperator. This operator may alsoreadand output extra column values necessary to find and delete rows from nonclustered indexes.
The iterative clustered index delete activity is driven by theEager Table Spoolon the top branch. The spool iseagerbecause it stores all the rows from its input into a worktable before returning the first row to its parent operator (theIndex Deleteon the top branch). The effect is that all qualifying base table rows are deletedbeforeany nonclustered index changes occur.
The spool in this plan is acommon subexpression spool. It is populated once, then acts as a row source for multiple consumers. In this case, the contents of the spool are consumed first by the top-branchIndex Delete, which removes index entries from one of the nonclustered indexes.
When theSequenceoperator switches to asking for rows from the lower branch, the spool is rewound and replays its contents to delete rows from the second nonclustered index. Note that the spool contains theunionof all columns required for all the nonclustered index changes.
2. Narrow, per-row updates
Narrow (aka per-row) updates have a single update operator that maintains the base table (heap or clustered index), and one or more nonclustered indexes. Each row arriving at the update operator updates all indexes associated with the operator before processing the next row. An example:
DECLARE @T table
(
pk integer PRIMARY KEY,
col1 integer NOT NULL UNIQUE,
col2 integer NOT NULL UNIQUE
);
DECLARE @S table
(
pk integer PRIMARY KEY,
col1 integer NOT NULL,
col2 integer NOT NULL);
INSERT @T (pk, col1)
SELECT
S.pk,
S.col1
FROM @S AS S;
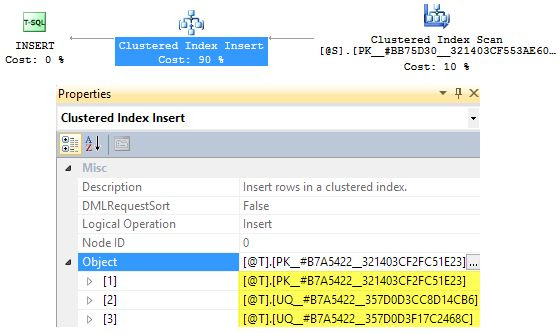
The execution plan viewed usingPlan Explorershows the nonclustered index maintenance explicitly. Hover over theClustered Index Insertfor a tooltip showing the names of the nonclustered indexes involved:
In SQL Server Management Studio, there is no information about the nonclustered index maintenance in the graphical plan or tooltips. We need to click on the update operator (Clustered Index Insert) and then check thePropertieswindow:
TheObjectsubtree shows the clustered index and two nonclustered indexes being maintained.
Cost-based choice
The query optimizer uses cost-based reasoning to decide whether to update each nonclustered index separately (per-index) or as part of the base table changes (per-row).
An example that updates one nonclustered index per-row, and another per-index is shown below:
CREATE TABLE #T
(
pk integer IDENTITY PRIMARY KEY,
col1 integer NOT NULL,
col2 varchar(8000) NOT NULL DEFAULT ''
);
CREATE INDEX nc1 ON #T (col1);
CREATE INDEX nc2 ON #T (col1) INCLUDE (col2);
INSERT #T
(col1)
SELECT
N.n
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 251;
The combination strategy can be seen with Plan Explorer:
The details are also displayed in the SSMS Properties window when theClustered Index Insertoperator is selected.
3. Single-operator updates
The third form of update is an optimization of the per-row update plan for very simple operations. The cost-based optimizer still emits a per-row update plan, but a rewrite is subsequently applied to collapse the reading and writing operations into a single operator:
DECLARE @T AS TABLE
(
pk integer PRIMARY KEY,
col1 integer NOT NULL
);
-- Simple operations
INSERT @T (pk, col1) VALUES (1, 1000);
UPDATE @T SET col1 = 1234 WHERE pk = 1;
DELETE @T WHERE pk = 1;
The complete execution plans (and extracts from the XML plans) are shown below:
TheUPDATEandDELETEplans have been collapsed to aSimple Updateoperation, while theINSERTis simplified to aScalar Insert.
We can see the optimizer output tree withtrace flag 8607:
Notice the two physical operators: AConstant Scan(in-memory table) containing the literal values specified in the query; and aStream Updatethat performs the database changes per row.
All three statements produce a similar optimizer tree output (and all use a stream update). We can prevent the single-operator optimization being applied with undocumentedtrace flag 8758:
This exposes the expanded per-row update plans produced by the optimizer before the single-operator rewrite:
Single operator plans can be significantly more efficient than the multiple-operator form in the right circumstances, for example if the plan is executedveryfrequently.
Update plan optimizations
From this point forward, I’m going to useAdventureWorksDELETEexamples, but the general points apply equally well toINSERT,UPDATE, andMERGEas well.
The examples will not have a complicatedSELECTcomponent, because I want to concentrate on the update side of the plan rather than the reading side.
Per-row updates
It’s worth emphasising that narrow update plans are an optimization that is not available for every update query (except for Hekaton where they are the default).
The optimizer favours a per-row plan if the expected number of rows at the update operator is low. In the example below, the optimizer expects to delete 25 rows:
This plan updates the base table (a clustered index in this case) and all nonclustered indexes in sequence per row. The row source here is an ordered scan of anonclusteredindex, which means rows willnotgenerally be presented in clustered index key order to the update operator.
An unordered stream like this tends to result in random I/O (assuming physical I/O is required). If the plan is expected to process only a small number of rows, the optimizer decides it is not worth adding extra operations to encourage a sequential I/O access pattern.
Unordered Prefetch
If the expected number of rows is a bit larger, the optimizer may decide to build a plan that appliesprefetchingto one or more update operators.
The basic idea is the same as ordinary prefetching (a.k.a read-ahead) for scans and range seeks. The engine looks ahead at the keys of the incoming stream and issues asynchronous I/O for pages that will be needed by the update operator soon.
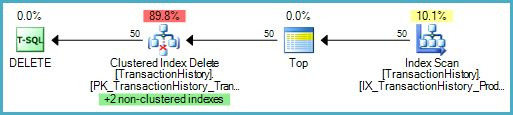
Prefetching can help reduce the impact of the expected random I/O. An example of prefetching on the update operator is shown below for the sameDELETEquery with an expected cardinality of 50 rows:
The prefetching isunorderedfrom the perspective of the clustered index. Neither SSMS nor Plan Explorer show the prefetch information prominently.
In Plan Explorer, we need to have theWith Unordered Prefetchoptional column selected. To do this, switch to the Plan Tree tab, open the Column Chooser, and drag the column to the grid. The unordered prefetch property is ticked for theClustered Index Deleteoperator in the screenshot below:
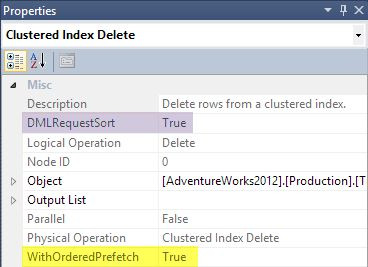
In SSMS, click on theClustered Index Deleteicon in the graphical plan, and then look in the Properties window:
If the query plan were reading from the clustered index (instead of a nonclustered index), the read operation would issue regular read-ahead, so there would be no point prefetching from theClustered Index Deleteas well.
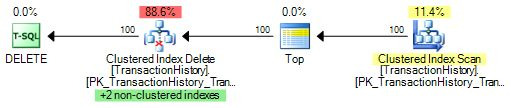
The example below shows the expected cardinality increased to 100, where the optimizer switches from scanning the nonclustered index withunorderedprefetching to scanning the clustered index with regular read-ahead. No prefetching occurs on the update operator in this plan:
Where the plan propertyWith Unordered Prefetchis not set, it is simply omitted—it does not appear set to False as you might expect.
Ordered Prefetch
Where rows are expected to arrive at an update operator in non-key order, the optimizer might consider adding an explicitSortoperator. The idea is that presenting rows in key order will encourage sequential I/O for the index pages.
The optimizer weighs the cost of sorting against the expected benefits of avoiding random I/O. The execution plan below shows an example of a sort being added for this reason:
The Sort is onTransaction ID, the clustering key for this table. With the incoming stream now sorted, the update operator can useorderedprefetching.
The plan is still scanning the nonclustered index on the read side, so read-ahead issued by that operator does not bring in the clustered index pages needed by the update operator.
Ordered prefetching tends to result in sequential I/O, compared with the mostly random I/O of unordered prefetching. TheWith Ordered Prefetchcolumn is also not shown by default by Plan Explorer, so it needs to be added as we did before:
Not every update operator with ordered prefetching requires a Sort. If the optimizer finds a plan that naturally presents keys in nonclustered index order, an update operator may still use ordered prefetching to pull pages we are about to modify into memory before they are requested by the update operator.
DML Request Sort
When the optimizer decides to explore a plan alternative thatrequiresordered input to an update operator, it will set theDML Request Sortproperty for that operator.
Plan Explorer shows this setting in the update operator tooltip:
SSMS showsWith Ordered PrefetchandDML Request Sortin the Properties window:
Nonclustered index updates
Sorting and ordered prefetching may also be considered for the nonclustered indexes in a wide update plan:
This plan shows all three update operators withDML Request Sortset.
TheClustered Index Deletedoes not require an explicit sort because rows are being read (with internal ordering guarantees) from theClustered Index Scan.
The two non-clustered indexes do require explicit sorting. Both nonclustered index update operators also use ordered prefetching; the clustered index update does not because the prior scan automatically invokes read-ahead for that index.
The next example shows that each update operator is considered separately for the various optimizations:
That plan featuresunorderedprefetching on theClustered Index Delete(because the row source is a scan of a nonclustered index), an explicitSortwithorderedprefetching on the top branchIndex Delete, andunorderedprefetching on the bottom branchIndex Delete.
The per-index and per-row update plan
Is the following aper-indexorper-rowupdate plan?
It appears to be aper-indexplan because there are two separate update operators, but there is no blocking operator (Eager SpoolorSort) between the two.
This plan is a pipeline. Each row returned from the seek will be processed first by theClustered Index Deleteand then by theIndex Delete. In that sense, both updates (clustered and nonclustered) areper-row.
Anyway, the important thing is not the terminology, it is being able to interpret the plan. Now we know what the various optimizations are for, we can see why the optimizer chose the plan above over the seemingly equivalent but more efficient-looking narrow plan:
The narrow plan has no prefetching. The Seek provides read-ahead for the clustered index pages, but the single non-clustered index has nothing to prefetch any pages from disk it might need.
By contrast, the wide update plan has two update operators. TheClustered Index Deletehas no prefetching for the same reason as in the narrow plan, but theIndex Deletehas unordered prefetchingenabled.
So, although the smaller narrow plan looks like it ought to be more efficient, it might perform less well if nonclustered index pages are required from disk and unordered prefetching proves effective.
On the other hand, if all required nonclustered index pages are in memory at the time the query is executed, the wide plan might perform less well since it features an extra operator and has to perform work associated with prefetching (even though ultimately no physical reads are issued).
Performance Impacts
You may have noticed a lack of performance numbers (I/O statistics, elapsed times and so on) in this post. There is a good reason for this. The optimizations presented here are quite dependent on SQL Server configuration and hardware. I don’t want you drawing general conclusions based on the performance of the rather ordinary single spinning hard drive in my laptop, the 256MB of RAM I have allowed for my SQL Server 2012 instance, and some rather trivialAdventureWorksexamples.
Which Optimizations are Good?
If the data structures you are changing are very likely to be in memory, and/or if you have averyfast random I/O system, the optimizer’s goal of minimizing random I/O and enhancing sequential I/O may not make much sense for you. The strategies the optimizer employs may well end up costing more than they save.
On the other hand, if your system has a much smaller buffer pool than database working set size, and your I/O system works very much faster with large sequential I/O than with smaller random I/O requests, you should generally find the optimizer makes reasonable choices for you, subject to the usual caveats about useful up-to-date statistics and accurate cardinality estimations.
If your system fits the optimizer’s model, at least to a first approximation, you will usually find that narrow update plans are best for low row-count update operations, unordered prefetching helps a bit when more rows are involved, ordered prefetching helps more, and explicit sorts before nonclustered index updates help most of all for the largest sets. That is the theory, anyway.
What are the Problems?
The problem I see most often is with the optimization that is supposed to help most: The explicitSortbefore a nonclustered index update.
The idea is that sorting the input to the index update in key order promotes sequential I/O, and often it does. The problem occurs if the workspace memory allocated to the Sort proves to be too small to perform it entirely in memory. The memory grant is fixed based on cardinality estimation and row size estimates, and may be reduced if the server is under memory pressure at the time.
ASortthat runs out of memory spills whole sort runs to physicaltempdbdisk, often repeatedly. This is often not good for performance, and can result in queries that complete very much slower than if theSorthad not been introduced at all.
Note:SQL Server reuses the generalSortoperator here — it does not have aSortspecially tuned for updates that could make abest effortto sort within the memory allocated, butneverspill to disk.
The narrow plan optimization can cause problems where it is selected due to a low cardinality estimate, where several nonclustered indexes need to be maintained, the necessary pages are not in memory, and the I/O system is slow at random reads.
The ordered and unordered prefetch options cause problems much more rarely. For a system with all data in memory, there is a small but possibly measurable impact due to the prefetch overhead (finding pages to consider read-ahead for, checking to see if they are already in the buffer pool, and so on). Even if no asynchronous I/O is ever issued by the worker, it still spends time on the task that it could spend doing real work.
What options are there?
The usual answer to deal with poor execution plan choices due to a system’s configuration or performance characteristics not matching the optimizer’s model is to try different T-SQL syntax, and/or to try query hints.
There are times when it is possible to rewrite the query to get a plan that performs better, and other times where rethinking the problem a bit can pay dividends. Various creative uses of partitioning, minimal logging, and bulk loading are possible in some cases, for example.
There are very few hints that can help with the update side of a plan that does not respond to the usual tricks, however. The two I use most often affect the optimizer’s cardinality estimation:OPTION (FAST n)and a trick involvingTOPand theOPTIMIZE FORquery hint.
OPTION (FAST n)affects cardinality estimates in a plan by setting a final row goal, but its effects can be difficult to predict, and may not have much of an effect if the plan contains blocking operators. Anyway, the general idea is to vary the value of ‘n’ in the hint until the optimizer chooses the desired plan shape or optimization options as described in this post. Best of luck with that.
The idea withTOPis similar, but often tends to work better in my experience. The trick is to declare abigintvariable with the number of rows the query should return (or a very large value such as the maximum value of abigintif all rows are required), use that as the parameter to aTOP, and then use theOPTIMIZE FORhint to set a value for ‘n’ that the optimizer should use when considering alternative plans. This option is particularly useful for encouraging a narrow plan.
Most of the examples in this post used theTOPtrick in the following general form:
DECLARE @n bigint = 9223372036854775807;
DELETE TOP (@n)
FROM Production.TransactionHistory
OPTION (OPTIMIZE FOR (@n = 50));
Magic trace flags
There are trace flags that affect the optimizations discussed in this post. They are undocumented and unsupported, and may only work on some versions, but they can be handy to validate a performance analysis, or to generate a plan guide for a particularly crucial query. They can also be fun to play with on a personal system to explore their effects. The main ones that affect the optimizations described here are:
2332 : Force DML Request Sort
8633 : Enable prefetch only
8744 : Disable prefetch only
8758 : Disable rewrite to a single operator plan
8790 : Force a wide update plan
8795 : Disable DML Request Sort
9115 : Disable optimized NLJ and prefetch
These trace flags can all be manipulated using the usualDBCCcommands or enabled temporarily for a particular query using theOPTION (QUERYTRACEON xxxx)hint.
Final Thoughts
The optimizer has a wide range of choices when building the writing side of an update plan. It may choose to update one or more indexes separately, or as part of the base table update. It may choose to explicitly sort rows as part of a per-index update strategy, and may elect to perform unordered or ordered prefetching as well.
As usual, these decisions are made based on costs computed using the optimizer’s model. This model may not always produce plans that are optimal for your hardware (and as usual the optimizer’s choices are only as good as the information you give it).
If a particular update query is performance critical for you, make sure cardinality estimates are reasonably accurate. Test with alternate syntax and/or trace flags to see if an alternative plan would perform significantly better in practice. It is usually possible to use documented techniques likeTOPclauses andOPTIMIZE FORhints to produce an execution plan that performs well. Where that is not possible, more advanced tricks and techniques like plan guides may be called for.
Thanks for reading. I hope this post was interesting and provided some new insights into update query optimization.
Today we are going to discuss about how to resolve the“Error 15141: The Server Principal Owns One or More Server Roles and cannot be dropped”
Introduction
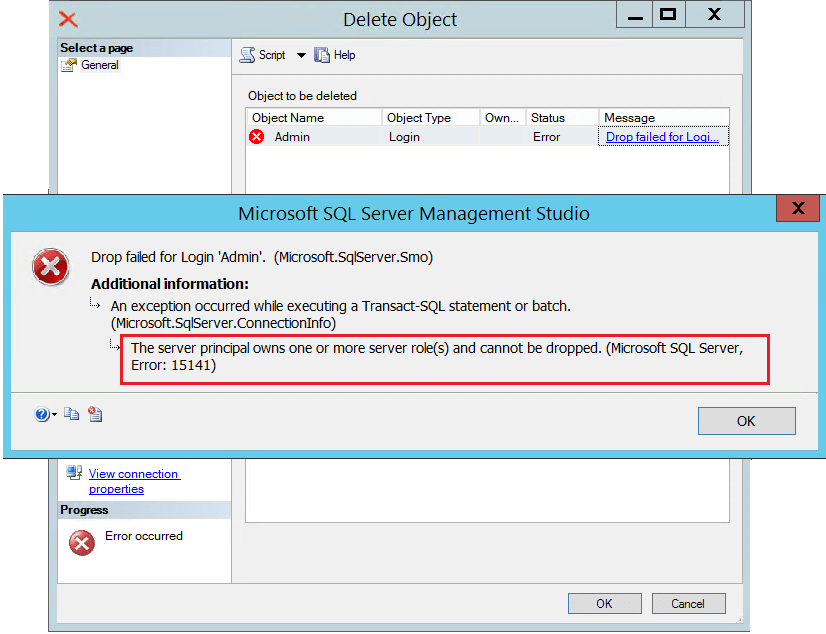
If you are a SQL Server DBA, you may encounter the Error 15141 when trying to delete a login id. First of all let me show you how the error message looks like in SSMS when you try to delete/drop a login.
In the above example screen shot we are trying to delete the login id ‘Admin’. I have observed that some DBA(s) do not read the error message carefully and starts beating about the bush.
There are very similar error messages while dropping logins as you can refer the following links:
To emphasize if you observe the above error message clearly reads that the principal (or login) owns one or more server roles, which prevents you from dropping it.
Cause Of the Error 15141: The Server Principal Owns One or More Server Roles
When a server principal or login owns a server role, you cannot drop the login unless you first transfer ownership of the server role to another login. As a matter of fact SQL Server never allows you to drop a login if it owns any object. Hence it throws the error preventing you to drop the server principal or login.
Resolution
To resolve the error, you first need to identify the Server Roles owned by the login or server principal. Then you need to transfer the ownership for each of the server roles to ‘sa’ or any other login as per your organization standard.
1. Query to Identify the Server Roles the Login owns
SELECT sp1.name AS ServerRoleName,
sp2.name AS RoleOwnerName
FROM sys.server_principals AS sp1
JOIN sys.server_principals As sp2
ON sp1.owning_principal_id=sp2.principal_id
WHERE sp2.name='Admin' --Change the login name
Sample Output:
Here in the above example it shows that the login id ‘Admin’ owns two Server roles. On the contrary if the login would have own one or more database role(s), it would allow to delete the login but not the user. Now we’ll change the ownership.
2. Query to Change the Server Role Owner:
USE [master]
GO
ALTER AUTHORIZATION ON SERVER ROLE :: [ServerRole-Test] TO [sa] --Change The ServerRole Name and login Name
GO
ALTER AUTHORIZATION ON SERVER ROLE :: [AnotherServerRole-Test] TO [sa] --Change The ServerRole Name and login Name
GO
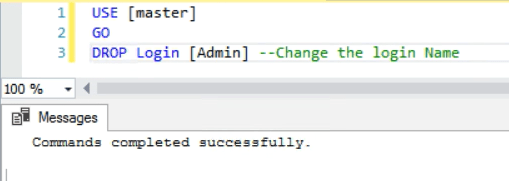
3. Drop the Login:
USE [master]
GO
DROP Login [Admin] --change the login Name
Query Result:
As can be seen now the the drop command completed successfully.
Conclusion:
To summarize the error Error 15141: The Server Principal Owns One or More Server Rolesand cannot be droppedoccurs when the login or server principal owns one or more Server Roles and you are trying to drop the login. Obviously you should not take any knee jerk reaction. After all you are trying to resolve the issue. Hence you should first list out the Server Roles which the login owns. Then change the ownership to [sa] or any other login as per your organization standards. Finally delete or drop the login. Definitely this should resolve the issue. Important to realize that this method will allow you to delete the login even if the login owns and database roles. Hence to repeat you need to be very careful while working in production systems.
10.36.192.0/19가 지정되어 있으므로, 2^(32-19) = 8192개 IP를 할당할 수 있는 VPC를 구성할 수 있다.
멀티존 구성을 위해 서브넷을 나누어야하고, ncloud는 KR-1, KR-2 2개의 존이 있으므로 할당받은 ip를 2개의 서브넷으로 나누면 각각 4096개 IP를 수용할 수 있는 2개의 서브넷을 구성할 수 있다. 2^(32-20) = 4096개 이므로 /20 CIDR(Classless Inter-Domain Routing)이 된다.
첫 번째 서브넷 1의 시작값은 10.36.192.0/20 이며, 두 번째 서브넷 2의 시작값은 10.36.208.0/20 이다.
두 번째 서브넷 2의 시작값 계산은 아래와 같이 할 수 있다. 4096 (서브넷의 가용 IP) / 256 (8bit) = 16 증가 3번째 옥텟값 192에서 16을 더하면 208이므로, 두 번째 서브넷 2는 10.36.208.0/20이 된다.