Dynamic Seeks and Hidden Implicit Conversions
https://www.sql.kiwi/2012/01/dynamic-seeks-and-hidden-implicit-conversions/
Dynamic Seeks and Hidden Implicit Conversions
SQL Server can generate dynamic seek plans, where a seek is driven by Constant Scan and Merge Interval operators. The plans use internal functions LikeRangeStart, LikeRangeEnd, and LikeRangeInfo. Watch out for hidden conversions using GetRangeThroughConver
www.sql.kiwi
Introduction
A LIKE predicate with only a trailing wildcard can usually use an index seek, as the following AdventureWorks sample database query shows:
SELECT
P.[Name]
FROM Production.Product AS P
WHERE
P.[Name] LIKE N'D%';
SQL Server determines a covering range, which depends on the collation. It seeks the string index using the range as the start and end points of a partial scan, and applies the original LIKE condition as a residual predicate. More specifically, the Storage Engine seeks the index to locate rows in the covering range, and the Query Processor applies the residual predicate (the LIKE) to the rows it receives back.
Dynamic Seeks
What if the LIKE search term is in a variable?
DECLARE
@Like nvarchar(50) = N'D%';
SELECT
P.[Name]
FROM Production.Product AS P
WHERE
p.[Name] LIKE @Like;SQL Server can still perform a seek here, but it needs to determine the covering seek range for the search term at execution time, not at compilation time:

The plan now contains an extra Constant Scan, a Compute Scalar and a Nested Loops Join. These operators are interesting because they have zero cost estimates: No CPU cost, no I/O cost, nothing. These new operators are purely architectural in nature. They are a workaround for the fact that SQL Server cannot currently perform a dynamic seek entirely within the Index Seek operator itself.
The optimizer’s output is:
*** Output Tree: (trivial plan) ***
PhyOp_Filter
PhyOp_Range TBL: Production.Product
ScaOp_Intrinsic like
ScaOp_Identifier QCOL: [P].Name
ScaOp_Identifier COL: @Like
ScaOp_Const TI(nvarchar ML=2)
ScaOp_Identifier COL: ConstExpr1002
ScaOp_Identifier COL: ConstExpr1003
ScaOp_Identifier COL: ConstExpr1004 The additional operators needed for dynamic seek execution are added after query optimization is complete, so they cannot affect plan choices. Since there is no more cost-based analysis to do, the extra machinery is given costs of zero.
Execution plan
Looking at the finished execution plan:
- The Constant Scan produces a single in-memory row with no columns.
- The Compute Scalar defines expressions to describe the covering seek range (using the runtime value of the @Like variable).
- The Nested Loops Join drives the seek using the computed range information (provided as correlated values).
The upper tooltip shows that the Compute Scalar uses three internal functions, LikeRangeStart, LikeRangeEnd, and LikeRangeInfo.
The first two functions describe the range as an open interval. The third function returns a set of flags encoded in an integer. These are used internally to define certain seek properties for the Storage Engine.
The lower tooltip shows the seek on the open interval described by the result of LikeRangeStart and LikeRangeEnd, together with the application of the residual predicate LIKE @Like.
More Dynamic Seeks
Something very similar occurs in plans that use IN or OR with variables:
DECLARE
@1 integer = 320,
@2 integer = 325,
@3 integer = 330;
SELECT
P.[Name]
FROM Production.Product AS P
WHERE
P.ProductID IN (@1,@2,@3);
Now we have three ranges: One for each of the variables in the original query. The Compute Scalar operators again define three columns containing the start and end of the range, and the associated informational flags (previously seen as a result of the LikeRangeInfo function). This time, we see the decimal representation of these flags, which happens to be 62 for an equality comparison.
The IN expands to ProductID = @1 OR ProductID = @2 OR ProductID = @3, so each of the ‘ranges’ here is in fact a single value. For this example, the start and end range values are therefore the same in each Compute Scalar. The three dynamic ranges are concatenated, and sorted so any overlapping ranges appear next to each other.
The Merge Interval collapses these intervals into one or more disjoint (non-overlapping) ranges. This is important, because the three variables might, for example, all contain the same value, and it would be incorrect to return that value three times.
For each disjoint range produced, the Nested Loops Join drives a new seek of the Clustered Index. The overall effect is that an arbitrary number of possibly overlapping ranges are computed, merged, and then used to drive one or more seek operations.
The final result of the query will be the combination of all the seek results.
Hidden Conversions
The following example contains a table with datetime2 values, and a query with a expression that at first sight seems unlikely to be able to seek on an index. The variable is typed as date, and there is a CONVERT function applied to the datetime2 column:
DECLARE @Example table
(date_time datetime2 PRIMARY KEY);
INSERT @Example
(date_time)
VALUES
('20110101 12:34:56');
DECLARE
@date date = '2011-01-01';
SELECT *
FROM @Example AS E
WHERE
@date = CONVERT(date, E.date_time);Nevertheless, an execution plan that uses a seek can be produced:

In this case, neither SSMS nor Plan Explorer will show the contents of the Compute Scalar. We have to open the XML representation of the execution plan to see the three familiar expressions, wrapped in a ValueVector (just a fancy container for multiple expressions).
Another internal function, GetRangeThroughConvert, is responsible for determining the range of datetime2 values covered by the date variable @date, and the informational flags needed. In the same way the engine works out covering ranges for some LIKE predicates, this function determines ranges where certain problematic type conversions are required.
Otherwise, the machinery is the same: A range description is defined by the Compute Scalar, and the Nested Loops Join driving a seek using those values.
More Hidden Conversions
There is another related internal function used when the Query Processor needs to determine a range for a comparison between different data types.
This example returns rows based on a greater-than-or-equal comparison between date column values and the datetime return value of the GETDATE() intrinsic function:
DECLARE @Example table
(col1 date PRIMARY KEY);
SELECT *
FROM @Example AS E
WHERE
E.col1 >= DATEADD(DAY, -7, GETDATE());
Again, the graphical plan cannot display the contents of the ValueVector, so we have to dig into the XML.
The function:
- Evaluates the DATEADD(GETDATE()) expression
- Computes the open-interval start point of a date range accounting for the conversion from datetime to date
- Specifies NULL as the end of the range (since this is a >= comparison, there is no end value).
The flags value in this case is 22 (representing a >= seek operation).
Everything All At Once
This last example features all sorts of data type sloppiness, resulting in an execution plan that uses:
- GetRangeThroughConvert on the string expression
- GetRangeThroughConvert on the result of
- GetRangeWithMismatchedTypes applied to the result of the GETDATE function.
The whole thing is then wrapped in a dynamic seek with the Merge Interval enforcing the (annoying) BETWEEN requirement that the first parameter must be less than or equal to the second.
See if you can work out all the conversions necessary for this query, using the rules of data type precedence.
It is really quite impressive that this example of lazy T-SQL coding still results in an index seek, don’t you think?
DECLARE @Example table
(col1 datetime PRIMARY KEY);
SELECT *
FROM @Example AS E
WHERE
CONVERT(date, E.col1) BETWEEN '20000101' AND GETDATE();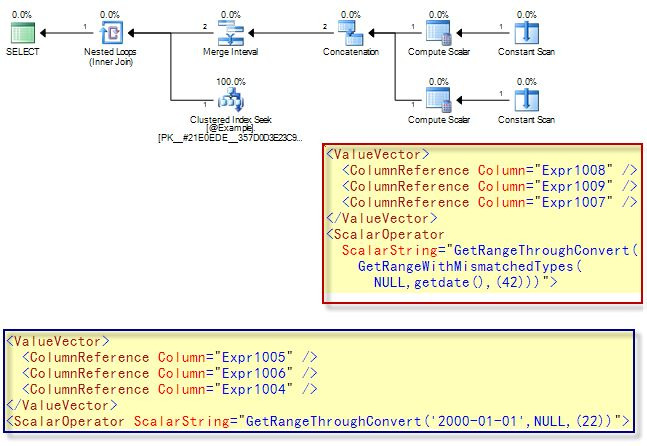
Conclusion
SQL Server works quite hard sometimes to produce index seeks where they might seem unlikely. This is a good thing, and it would be great to see this capability extended further in future. The downside is that this extra effort means you are less likely to see an Index Scan when you have done something daft with data types.
Why is this a bad thing if you get a seek anyway?
The problem is that these hidden implicit conversions can result in inaccurate cardinality and distribution estimates at any stage of the plan. So, even if you get a seek, the plan might be way off overall.
If that isn’t persuasive enough, consider this: Will having hidden nested range calculations improve your chances of getting a good query plan? Probably not, no.
Be very aware of data types in general, and in particular of the data types returned by system functions and T-SQL expressions. If in doubt, use SELECT INTO to materialize the result of an expression or query, and check the types of the columns produced.
Note: If you have any scripts that trawl the plan cache looking for implicit conversions (CONVERT_IMPLICIT), you might want to look into updating them to check for these conversions too. Remember that not all conversions are bad though.
Related Reading
- Implicit Conversions by Craig Freedman.
- More on Implicit Conversions also by Craig Freedman.
- Join Performance, Implicit Conversions, and Residuals by me.
- Trigram Wildcard Search in SQL Server also by me.
--*****************************************************************
-- 아래 이슈는 변수로 들어오는 인자를 테이블 컬럼타입과 일치시켜 varchar(10) 으로 변환해주면 효율적으로 처리 가능합니다.
--*****************************************************************
-- 테이블
CREATE TABLE dbo.RandomData
(
Id INT IDENTITY(1,1) PRIMARY KEY,
RandomString VARCHAR(10) NOT NULL
);
GO
-- 데이터 삽입
INSERT INTO dbo.RandomData(RandomString)
SELECT LEFT(REPLACE(CONVERT(VARCHAR(36), NEWID()),'-','')
+ REPLACE(CONVERT(VARCHAR(36), NEWID()),'-',''), 10)
FROM (
SELECT TOP (100000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS n
FROM sys.all_objects a
CROSS JOIN sys.all_objects b
) AS x;
GO 3
-- 인덱스
create nonclustered index nc_RandomData_01 on RandomData (RandomString)
go
-- i/o 통계
set statistics io , time on
go
-- 전체를 count 시
select count(*) from RandomData
-----------
300000
(1개 행 적용됨)
--*****************************************************************
테이블 'RandomData'. 스캔 수 1, 논리적 읽기 1494, 실제 읽기 0, 페이지 서버 읽기 0, 미리 읽기 읽기 0, 페이지 서버 미리 읽기 읽기 0, lob 논리적 읽기 0, lob 실제 읽기 0, lob 페이지 서버 읽기 0, lob 미리 읽기 읽기 0, lob 페이지 서버 미리 읽기 읽기 0.
--*****************************************************************
-- 잘동작하는 경우
select count(*) from RandomData where RandomString = N'z'
select count(*) from RandomData where RandomString = N'aaaaaaaaaa'
select count(*) from RandomData where RandomString = N'zzzzzzzzzz'
select count(*) from RandomData where RandomString = N' '
-----------
0
(1개 행 적용됨)
--*****************************************************************
테이블 'RandomData'. 스캔 수 1, 논리적 읽기 3, 실제 읽기 0, 페이지 서버 읽기 0, 미리 읽기 읽기 0, 페이지 서버 미리 읽기 읽기 0, lob 논리적 읽기 0, lob 실제 읽기 0, lob 페이지 서버 읽기 0, lob 미리 읽기 읽기 0, lob 페이지 서버 미리 읽기 읽기 0.
--*****************************************************************
-- GetRangeThroughConvert 함수값이 비효율 적인 경우
select count(*) from RandomData where RandomString = N'0'
select count(*) from RandomData where RandomString = N'a'
-----------
0
(1개 행 적용됨)
--*****************************************************************
테이블 'RandomData'. 스캔 수 1, 논리적 읽기 93, 실제 읽기 0, 페이지 서버 읽기 0, 미리 읽기 읽기 0, 페이지 서버 미리 읽기 읽기 0, lob 논리적 읽기 0, lob 실제 읽기 0, lob 페이지 서버 읽기 0, lob 미리 읽기 읽기 0, lob 페이지 서버 미리 읽기 읽기 0.
--*****************************************************************
-- GetRangeThroughConvert 함수값이 매우 비효율 적인 경우
select count(*) from RandomData where RandomString = N''
select count(*) from RandomData where RandomString = N'0123456789012'
CPU 시간 = 0ms, 경과 시간 = 0ms.
-----------
0
(1개 행 적용됨)
--*****************************************************************
테이블 'RandomData'. 스캔 수 1, 논리적 읽기 1494, 실제 읽기 0, 페이지 서버 읽기 0, 미리 읽기 읽기 0, 페이지 서버 미리 읽기 읽기 0, lob 논리적 읽기 0, lob 실제 읽기 0, lob 페이지 서버 읽기 0, lob 미리 읽기 읽기 0, lob 페이지 서버 미리 읽기 읽기 0.
--*****************************************************************