
ddl trigger
카테고리 없음 / 2013. 1. 24. 01:53

|
병렬처리는 어떤 제한에 의해서 전체가 병렬로 처리되지 못하는 경우와
어떤 한 이터레이터만 병렬로 처리되지 못하는 경우가 있다. 이때는 TF 8649를 설정해도 병렬처리가 불가능 하다.
그러나, TF 8649로 강제로 병렬처리되는 쿼리가 비용이 높은데도 불구하고 힌트없이 돌리면 병렬로 처리되지 않는 이유는 뭘까? 이유는 간단했다. 싱글 처리가 병렬처리보다 계산된 예상비용이 작은 경우이다. MS 에서 병렬처리가 불가능 할때 TF8649를 이용한 테스트를 하라는 것은 이걸 테스트 해보라는 의미이다.
병렬처리의 비용은 CPU 수가 많아지면 논리 코어수의 절반까지는 비용이 줄어든다.
그러므로 코어수가 작은 서버에서 병렬처리가 안되던 것이 코어수가 많아지면 병렬처리가 되는 경우도 발생하는데
이유는 같다.
impersonate 가능 사용자 만들기
--CREATE LOGIN MS_BACKUP_OP WITH PASSWORD = 'P@ssw0rd' -- 로그인생성
--GO
--USE MASTER
--GO
--CREATE USER MS_BACKUP_OP FOR LOGIN MS_BACKUP_OP -- User 생성
--GO
--GRANT EXECUTE TO MS_BACKUP_OP -- 프로시저 실행권한
--GO
--ALTER SERVER ROLE [DISKADMIN] ADD MEMBER [MS_BACKUP_OP] -- 백업할 디바이스 생성을 위해 diskadmin 필요
--GO
--USE [DB_PLAN_GUIDE_TEST]
--GO
--CREATE USER MS_BACKUP_OP FOR LOGIN MS_BACKUP_OP
--GO
--ALTER ROLE [DB_BACKUPOPERATOR] ADD MEMBER [MS_BACKUP_OP] -- 해당 데이터베이스에 db_backupoperator role 필요
--GO
백업 권한을 위한 계정은 로그인이 불가능하게 만든다.
SYSADMIN 계정을 하나 만들어 두고 이렇게 설정하고 쓰면 될 듯
USE [master]
GO
DENY CONNECT SQL TO [ms_backup_op]
GO
ALTER LOGIN [ms_backup_op] DISABLE
GO
IF OBJECT_ID('AP_DB_BACKUP') IS NULL
EXEC ('CREATE PROC DBO.AP_DB_BACKUP AS SELECT 1 ')
GO
ALTER PROC [DBO].AP_DB_BACKUP
@DBNAME VARCHAR(100) = 'MASTER' -- BACKUP TARGET DATABASE
, @PATH VARCHAR(100) = 'C:\BACKUP\' -- OS BACKUP PATH
, @BACKUP_TYPE VARCHAR(1) = 'F' -- F FULLBACKUP L LOGBACKUP D DIFFERENTIAL
, @BEFORE_TARGET_TIME_HH INT = 2 -- DELETE FILE BEFORE TIME HH
AS
-- 계정 생성후 로그인 불가 처리한다.
EXECUTE AS login = 'sa' -- *DISKADMIN*DB_BACKUPOPERATOR*
SET NOCOUNT ON
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
-- SCRIPT BY MINSOUK KIM
-- VERSION 1.20130104
-- BLOG, SQLSQL.TISTORY.COM
-- MAIL, MINSOUK@HOTMAIL.COM
-- xp_cmdshell 제거
-- 특정 유저로 백업
IF @BACKUP_TYPE = 'L'
WAITFOR DELAY '00:00:03.000'
IF @BACKUP_TYPE = 'D'
WAITFOR DELAY '00:00:10.000'
DECLARE @CAL_BEFORE_TARGET_TIME DATETIME
, @DEL_TARGET_DEV_NAME VARCHAR(500)
, @CUR_TARGET_DEV_NAME VARCHAR(500)
, @DATE VARCHAR(500)
, @TIME VARCHAR(500)
, @PHYSICAL_NAME VARCHAR(500)
, @TODAY VARCHAR(8)
, @INSTANCE_NAME VARCHAR(500)
SELECT @INSTANCE_NAME = REPLACE(@@SERVERNAME , '\','_')
, @DATE = CONVERT(VARCHAR(100), GETDATE(), 112)
, @TIME = REPLACE(CONVERT(VARCHAR(100), GETDATE(), 108),':','')
select @instance_name , @date, @time
SELECT @CAL_BEFORE_TARGET_TIME = DATEADD(HH,-1*ABS(@BEFORE_TARGET_TIME_HH),GETDATE())
DECLARE @LOG_BACKUP_DELETE_TARGET TABLE
(IDX INT IDENTITY(1,1)
,NAME VARCHAR(500)
)
INSERT INTO @LOG_BACKUP_DELETE_TARGET (NAME)
SELECT NAME
FROM MASTER.DBO.SYSDEVICES
WHERE ISDATE(LEFT(RIGHT(NAME, 15),8)) = 1
AND CAST(REPLACE(STUFF(STUFF(RIGHT(NAME, 15),12,0,':'),15,0,':'),'_',' ') AS DATETIME) < @CAL_BEFORE_TARGET_TIME
AND NAME LIKE 'SQL'+@BACKUP_TYPE+'B_' +REPLACE(@@SERVERNAME,'\','_') +'_'+@DBNAME+'%'
ORDER BY 1
select * from @LOG_BACKUP_DELETE_TARGET
DECLARE @MAX_IDX INT
SELECT TOP 1 @MAX_IDX = IDX
FROM @LOG_BACKUP_DELETE_TARGET
ORDER BY IDX DESC
WHILE (@MAX_IDX > 0) BEGIN
SELECT @DEL_TARGET_DEV_NAME = NAME
FROM @LOG_BACKUP_DELETE_TARGET
WHERE IDX = @MAX_IDX
IF @@ROWCOUNT = 0 BREAK;
BEGIN TRY
EXEC SP_DROPDEVICE @DEL_TARGET_DEV_NAME,'DELFILE'
END TRY BEGIN CATCH
SELECT 'ERROR !'
END CATCH
SET @MAX_IDX = @MAX_IDX - 1
END
SELECT @CUR_TARGET_DEV_NAME = UPPER(
'SQL'+@BACKUP_TYPE+'B_'
+ REPLACE(@@SERVERNAME,'\','_') + '_'
+ @DBNAME + '_'
+ @DATE+'_'
+ @TIME
)
, @PHYSICAL_NAME = UPPER(
RTRIM(@PATH+@INSTANCE_NAME)
+ '\'
+ REPLACE(@@SERVERNAME,'\','_') + '_'
+ 'SQL'+@BACKUP_TYPE + 'B_'
+ LEFT(@DBNAME+ '_' + REPLICATE (@BACKUP_TYPE, 40),40) + '_'
+ @DATE + '_'
+ @TIME
+ '.'
+ @BACKUP_TYPE
+ 'BAK'
)
SELECT @CUR_TARGET_DEV_NAME DEV_NAME
, @PHYSICAL_NAME PATH_NAME
EXEC SP_ADDUMPDEVICE 'DISK' , @CUR_TARGET_DEV_NAME , @PHYSICAL_NAME
IF @BACKUP_TYPE = 'F'
BACKUP DATABASE @DBNAME TO @CUR_TARGET_DEV_NAME WITH INIT
, NAME = @CUR_TARGET_DEV_NAME
, NOSKIP
, NOFORMAT
--, PASSWORD = 'P@SSW0RD'
IF @BACKUP_TYPE = 'L'
BACKUP LOG @DBNAME TO @CUR_TARGET_DEV_NAME
IF @BACKUP_TYPE = 'D'
BACKUP DATABASE @DBNAME TO @CUR_TARGET_DEV_NAME WITH INIT
, NAME = @CUR_TARGET_DEV_NAME
, NOSKIP
, NOFORMAT
, DIFFERENTIAL
go
exec master.dbo.ap_db_backup 'master','e:\backup2\','F',1
--declare @BMK varchar(max)
--set @BMK = 'BACKUP SERVICE MASTER KEY TO FILE = ''E:\BACKUP_SQLTAG\' + replace(@@servername,'\','_') + '.service_master.key'' ENCRYPTION BY PASSWORD = ''P@SSW0RD'''
--exec (@BMK)
--RESTORE SERVICE MASTER KEY FROM FILE = 'E:\BACKUP_SQLTAG\filename' DECRYPTION BY PASSWORD = 'P@SSW0RD' -- [FORCE]
IF OBJECT_ID('AP_DB_BACKUP_ENZIP') IS NULL
EXEC ('CREATE PROC AP_DB_BACKUP_ENZIP AS SELECT 1 ')
GO
ALTER PROC AP_DB_BACKUP_ENZIP
(
@DBNAME VARCHAR(20) = 'MASTER' -- BACKUP TARGET DATABASE
, @BEFORE_TARGET_TIME_HH INT = 0 -- DELETE FILE BEFORE TIME HH
, @COMPRESS_0123 VARCHAR(100) = '0' -- 0은 압축하지 않음
, @PASSWORD VARCHAR(100) = 'MINSOUK'
)
AS
SET NOCOUNT ON
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
-- 7ZIP COMMANDLINE 프로그램을 C:\WINDOWS\SYSTEM32 에 넣어줘야 한다.
-- SP_CONFIGURE XP_CMDSHELL 확인하고 원복한다.
-- 작업파일 시간전 예전파일을 지우고 시작한다.
-- fbak 파일이 없으면 그냥 끝난다.
-- VERSION 20131115
IF NOT EXISTS (SELECT * FROM MASTER.INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME = 'AP_DB_BACKUP_ENZIP_HISTORY')
BEGIN
EXEC ('
CREATE TABLE MASTER.DBO.AP_DB_BACKUP_ENZIP_HISTORY
(
IDX INT IDENTITY(1,1) PRIMARY KEY
, DBNAME NVARCHAR(50)
, EN_ZIP_TIME DATETIME
, EN_ZIP_FILENAME NVARCHAR(1000)
, PHYNAME NVARCHAR(1000)
)
')
END
DECLARE @LOG_BACKUP_DELETE_TARGET TABLE
(IDX INT IDENTITY(1,1)
,NAME VARCHAR(1000)
)
DECLARE @CAL_BEFORE_TARGET_TIME DATETIME = DATEADD(HOUR,-1*ABS(@BEFORE_TARGET_TIME_HH),GETDATE())
, @PHYNAME NVARCHAR(1000)
, @CMD_STRING NVARCHAR(1000)
, @DEL_TARGET_DEV_NAME VARCHAR(1000)
, @FILE_EXISTS INT
INSERT INTO @LOG_BACKUP_DELETE_TARGET
SELECT EN_ZIP_FILENAME
FROM MASTER.DBO.AP_DB_BACKUP_ENZIP_HISTORY
WHERE EN_ZIP_TIME < @CAL_BEFORE_TARGET_TIME
DECLARE @MAX_IDX INT
SELECT TOP 1 @MAX_IDX = IDX
FROM @LOG_BACKUP_DELETE_TARGET
ORDER BY IDX DESC
WHILE (@MAX_IDX > 0)
BEGIN
SELECT @DEL_TARGET_DEV_NAME = NAME
FROM @LOG_BACKUP_DELETE_TARGET
WHERE IDX = @MAX_IDX
IF @@ROWCOUNT = 0 BREAK;
BEGIN TRY
SET @CMD_STRING = 'DEL '+ @DEL_TARGET_DEV_NAME
DELETE MASTER..AP_DB_BACKUP_ENZIP_HISTORY WHERE EN_ZIP_FILENAME = @DEL_TARGET_DEV_NAME
EXEC MASTER..XP_CMDSHELL @CMD_STRING, NO_OUTPUT
SELECT @CMD_STRING
SELECT 1
END TRY
BEGIN CATCH
DELETE MASTER..AP_DB_BACKUP_ENZIP_HISTORY WHERE EN_ZIP_FILENAME = @DEL_TARGET_DEV_NAME
SELECT 'ERROR !'
END CATCH
SET @MAX_IDX -= 1
END
SELECT TOP 1 @PHYNAME = A.PHYNAME
FROM MASTER..SYSDEVICES A
LEFT OUTER JOIN MASTER..AP_DB_BACKUP_ENZIP_HISTORY B
ON A.PHYNAME = B.PHYNAME
WHERE NAME LIKE '%'+'SQLFB_'+ REPLACE(@@SERVERNAME,'\','_')+'_'+ @DBNAME+'%'
AND B.PHYNAME IS NULL
ORDER BY RIGHT (NAME, 15) DESC
IF @PHYNAME IS NULL OR @PHYNAME = ''
BEGIN
SELECT 'EXECUTE AP_DB_BACKUP FIRST!'
RETURN 0
END
DECLARE @TBL_SP_CONFIGURE TABLE (NAME VARCHAR(100), MINIMUM INT, MAXMUM INT, CONFIG_VALUE INT, RUN_VALUE INT)
DECLARE @PREVIOUS_XP_CMDSHELL_BIT INT
INSERT INTO @TBL_SP_CONFIGURE EXEC SP_CONFIGURE 'XP_CMDSHELL'
SELECT @PREVIOUS_XP_CMDSHELL_BIT = RUN_VALUE
FROM @TBL_SP_CONFIGURE
IF @PREVIOUS_XP_CMDSHELL_BIT = 0
BEGIN
EXEC SP_CONFIGURE 'XP_CMDSHELL' ,1
RECONFIGURE WITH OVERRIDE
END
EXEC MASTER.DBO.XP_FILEEXIST @PHYNAME, @FILE_EXISTS OUT
IF @FILE_EXISTS = 1
BEGIN
-- CASE SENSETIVE
set @cmd_string = '7za.exe a -p'+@password+' -mx'+@compress_0123+' -t7z '+@phyname+'.ENZIP ' + @phyname
-- CASE SENSETIVE
EXEC MASTER..XP_CMDSHELL @CMD_STRING, NO_OUTPUT
SET @CMD_STRING = 'DEL '+ @PHYNAME
EXEC MASTER..XP_CMDSHELL @CMD_STRING, NO_OUTPUT
INSERT INTO MASTER.DBO.AP_DB_BACKUP_ENZIP_HISTORY (DBNAME, EN_ZIP_TIME, EN_ZIP_FILENAME, PHYNAME) VALUES (@DBNAME, GETDATE(), @PHYNAME+'.ENZIP',@PHYNAME)
END
IF @PREVIOUS_XP_CMDSHELL_BIT = 0
BEGIN
EXEC SP_CONFIGURE 'XP_CMDSHELL' ,0
RECONFIGURE WITH OVERRIDE
END
GO
Sath, The PPP adapter is created by Dial-Up Networking. Un-installing
Dial-Up Networking (Control Panel | Add/Remove Programs | Windows
Setup | Communications) will remove it. It will also prevent the
computer from making a dial-up Internet connection.
이라고 합니다.
http://www.windowskb.com/Uwe/Forum.aspx/windows-me-networking/1557/PPP-Adapter
사보텐더님 고맙습니다
망할 잡놈해커가
레지스트리키에 해당 스냅인을 disable 시켜 놔서
라우터및원격억세스 관리자가 실행이 안되었었습니다
다시말해
HKEY_CURRENT_USER\Software\Policies\Microsoft\MMC 항목에
restrict_run 항목을 지웠더니 .. 관리자가 실행이 되었고
서비스를 멈출 수 있었습니다
ARP 스푸핑 공격을 당한거라고 하는데
어디서 어떻게 고쳐야 할지 .. 아직 감감이네요 ..
고맙습니다
ARP 스푸핑(ARP spoofing)은 근거리 통신망(LAN) 하에서 주소 결정 프로토콜(ARP) 메시지를 이용하여 상대방의 데이터 패킷을 중간에서 가로채는 맨 인 더 미들 공격 기법이다.
로컬 영역 네트워크에서 각 장비의 IP 주소와 MAC 주소간의 대응은 ARP 프로토콜을 통해 이루어진다. 이때 공격자가 의도적으로 특정 IP 주소와 자신의 MAC 주소로 대응하는 ARP 메시지를 발송하면, 그 메시지를 받은 장비는 IP 주소를 공격자 MAC 주소로 인식하게 되고, 해당 IP 주소로 보낼 패킷을 공격자로 전송하게 된다. 이 때 공격자는 그 패킷을 원하는 대로 변조한 다음 원래 목적지 MAC 주소로 발송하는 공격을 할 수도 있다.
흔히 사용되는 공격 방식은 게이트웨이 IP를 스푸핑하는 것으로, 이 경우 외부로 전송되는 모든 패킷이 공격자에 의해 가로채거나 변조될 수 있다. 또는, 두 노드에 각각 ARP 스푸핑을 하여 두 장비의 통신을 중간에서 조작하는 기법도 자주 사용된다.
[2007년 6월] ARP Spoofing의 습격, 그리고 방어 전략
이번에 학교 네트워크에 전체적으로 ARP 스푸핑 웜이 돌아다니고 있어 네트워크가 불안 불안하다..
역시나 연구실에서도 몇개가 발견되고..
웹브라우저를 사용하면 이상한 사이트로 거쳐서 돌아온다거나 하는 사태가 발생해서..
여러가지로 알아보고 대응책을 강구해보았다.
0. 기본적인 도구 사용법
- 관리자로 접속해서 도구 사용
Microsoft Windows [Version 5.2.3790] (C) Copyright 1985-2003 Microsoft Corp. C:\Documents and Settings\Administrator>arp -a Interface: 155.230.90.97 --- 0x2 Internet Address Physical Address Type 155.230.88.1 00-04-96-15-36-90 dynamic 155.230.88.5 00-04-96-20-b9-b9 dynamic C:\Documents and Settings\Administrator>C:\Documents and Settings\Administrator>arp -a Interface: 155.230.90.97 --- 0x2 Internet Address Physical Address Type 155.230.88.1 00-04-96-15-36-90 dynamic 155.230.88.5 00-04-96-20-b9-b9 dynamic C:\Documents and Settings\Administrator>arp -a Interface: 155.230.90.97 --- 0x2 Internet Address Physical Address Type 155.230.88.1 00-04-96-15-36-90 dynamic 155.230.88.5 00-16-17-6a-f1-5a dynamic C:\Documents and Settings\Administrator>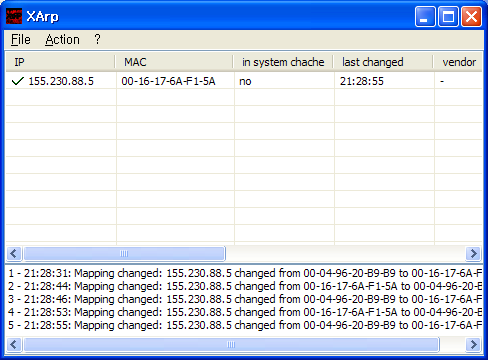
Microsoft Windows [Version 5.2.3790] (C) Copyright 1985-2003 Microsoft Corp. C:\Documents and Settings\Administrator>arp -a Interface: 155.230.90.97 --- 0x2 Internet Address Physical Address Type 155.230.88.5 00-16-17-6a-f1-5a dynamic 155.230.90.140 00-1a-4d-48-91-dc dynamic C:\Documents and Settings\Administrator>arp -s 155.230.88.5 00-04-96-20-b9-b9 C:\Documents and Settings\Administrator>arp -a Interface: 155.230.90.97 --- 0x2 Internet Address Physical Address Type 155.230.88.5 00-04-96-20-b9-b9 static 155.230.90.140 00-1a-4d-48-91-dc dynamic C:\Documents and Settings\Administrator>arp -d 155.230.90.140 C:\Documents and Settings\Administrator>arp -a Interface: 155.230.90.97 --- 0x2 Internet Address Physical Address Type 155.230.88.5 00-04-96-20-b9-b9 static C:\Documents and Settings\Administrator>Microsoft Windows [Version 6.0.6000] (C) Copyright 1985-2005 Microsoft Corp. C:\Users\Administrator>netsh -c "interface ipv4" netsh interface ipv4>show addresses "로컬 영역 연결" 인터페이스에 대한 구성 DHCP 사용: No IP 주소: 155.230.90.140 서브넷 접두사: 155.230.88.0/22(마스크 255.255.252.0) 기본 게이트웨이: 155.230.88.5 게이트웨이 메트릭: 256 인터페이스 메트릭: 20 "Loopback Pseudo-Interface 1" 인터페이스에 대한 구성 DHCP 사용: No IP 주소: 127.0.0.1 서브넷 접두사: 127.0.0.0/8(마스크 255.0.0.0) 인터페이스 메트릭: 50 netsh interface ipv4>set neighbors "로컬 영역 연결" "155.230.88.5" "00-04-96-20-b9-b9" netsh interface ipv4>exit C:\Users\Administrator>arp -a 인터페이스: 155.230.90.140 --- 0x8 인터넷 주소 물리적 주소 유형 155.230.88.5 00-04-96-20-b9-b9 정적 155.230.90.88 00-a0-b0-1b-5f-db 동적 C:\Users\Administrator>
4. 네트워크 관리자의 대응
- 감염원 파악
A. 여담
- 비상사태는 비상사태고 퇴근시간은 퇴근시간?
해커는 다음 파라미터를 수정해 또다른 포트로 서비스 가능하다
Thank you for your post here.
Did you install the security updateKB951746 (MS08-037) on the Windows Server 2003 server?
If yes, please check how it works if you create portreservation for PPTP.
1. On the server, locate the following registry keys in Regiedit:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\ReservedPorts
2. Add 1723-1723 to reserve the port needed forPPTP
3. Reboot the server to check how it works.
Some Services May Fail to Start or May Not Work Properly After Installing MS08-037 (951746 and 951748)
If you have any questions or concerns, please do not hesitate to let me know.
http://cafe.naver.com/sqlmvp/3487
dbcc freeproccache
go
drop table tblx
go
create table tblx
(idx int
,a int
,b int)
go
create clustered index nc_tblx_01 on tblx (idx)
create nonclustered index nc_tblx_02 on tblx (a)
--dbcc show_statistics (tblx, nc_tblx_01)
--dbcc show_statistics (tblx, nc_tblx_02)
if OBJECT_ID ('usp_cluster') is null
exec ('create proc usp_cluster as select 1 ')
go
if OBJECT_ID ('usp_covered') is null
exec ('create proc usp_covered as select 1 ')
go
if OBJECT_ID ('usp_none_covered') is null
exec ('create proc usp_none_covered as select 1 ')
go
alter proc usp_cluster
@a int
as
select * from tblx where idx = @a
go
alter proc usp_covered
@a int
as
select a from tblx where a = @a
go
alter proc usp_none_covered
@a int
as
select * from tblx where a = @a
go
set nocount on
declare @init int = 0
while (@init < 10000) begin
insert into tblx values (1,@init,1)
set @init += 1
end
go
exec dbo.usp_cluster 1
go 10
exec dbo.usp_covered 1
go 10
exec dbo.usp_none_covered 1
go 10
select refcounts, usecounts, plan_generation_num, text, *
from sys.dm_exec_query_stats a
cross apply sys.dm_exec_sql_text (a.sql_handle) b
left outer join sys.dm_exec_cached_plans c
on a.plan_handle = c.plan_handle
where text like '%tblx%'
and text not like '%sys.dm%'
and text not like '%insert%'
go
set nocount on
declare @init int = 0
while (@init < 10000) begin
insert into tblx values (1,@init,1)
set @init += 1
end
go
-- 여기서 부터 프로파일링 잡을것
exec dbo.usp_cluster 1
go
exec dbo.usp_covered 1
go
exec dbo.usp_none_covered 1
go
select refcounts, usecounts, plan_generation_num, text, *
from sys.dm_exec_query_stats a
cross apply sys.dm_exec_sql_text (a.sql_handle) b
left outer join sys.dm_exec_cached_plans c
on a.plan_handle = c.plan_handle
where text like '%tblx%'
and text not like '%sys.dm%'
and text not like '%insert%'
go
프로시저가 플랜을 재컴파일이 일어남을 잡는 방법 및 재컴파일시 결과
clustered index 만 재컴파일 일어나도록 했고, 나머지는 돌리지 않은 결과 입니다.
아래 테스트는 ISV 에서 만든 어플리케이션과 같이 특수한 환경에서 쿼리를 직접 고치지 못할 때 유용한 쿼리 힌트 방법이다. 특히 AD-HOC 쿼리로 들어오는 쿼리를 OPTIMIZE FOR 등의 방법으로 쿼리 힌트를 구현하고자 할 때 매우 유용한 방법이다. 스터디에서 OPTIMIZE FOR 의 설명은 많이 했으므로, 해당 설명은 생략 하도록 하겠다.
아래 내용은 편집해서 출판 할 것이므로, 그전에 오류나 추가할 내용 가이드 주세요~ ^.^
12년 12월 11일 update
USE MASTER
GO
IF EXISTS (SELECT * FROM SYS.DATABASES WHERE NAME ='DB_PLAN_GUIDE_TEST')
BEGIN
ALTER DATABASE DB_PLAN_GUIDE_TEST SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE DB_PLAN_GUIDE_TEST
END
GO
CREATE DATABASE DB_PLAN_GUIDE_TEST
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'DB_PLAN_GUIDE_TEST', FILENAME = N'L:\MSSQL\DB_PLAN_GUIDE_TEST.MDF' , SIZE = 100MB , MAXSIZE = UNLIMITED, FILEGROWTH = 100MB )
LOG ON
( NAME = N'DB_PLAN_GUIDE_TEST_LOG', FILENAME = N'L:\MSSQL\DB_PLAN_GUIDE_TEST_LOG.LDF' , SIZE = 100MB , MAXSIZE = 2048GB , FILEGROWTH = 100MB )
GO
USE DB_PLAN_GUIDE_TEST
GO
-- 기본 상태로 만든다.
ALTER DATABASE DB_PLAN_GUIDE_TEST SET PARAMETERIZATION SIMPLE
GO
SELECT * FROM SYS.plan_guides
GO
IF EXISTS (SELECT * FROM SYS.plan_guides WHERE NAME ='PLAN_GUIDE_TEST1')
EXEC SP_CONTROL_PLAN_GUIDE N'DROP', PLAN_GUIDE_TEST1
GO
IF EXISTS (SELECT * FROM SYS.plan_guides WHERE NAME ='PLAN_GUIDE_TEST2')
EXEC SP_CONTROL_PLAN_GUIDE N'DROP', PLAN_GUIDE_TEST2
GO
IF EXISTS (SELECT * FROM SYS.plan_guides WHERE NAME ='PLAN_GUIDE_TEST3')
EXEC SP_CONTROL_PLAN_GUIDE N'DROP', PLAN_GUIDE_TEST3
GO
IF OBJECT_ID ('TBLX') IS NOT NULL
DROP TABLE TBLX
GO
WITH TEMP AS
(
SELECT TOP 1000000
CAST(ROW_NUMBER() OVER (ORDER BY (SELECT 1)) AS INT) IDX
, 'PNAME_'+RIGHT(REPLICATE('0',7)+CAST(CAST(ABS(CHECKSUM(NEWID())) % 1000 AS INT) AS VARCHAR(10)),7)+CHAR(ASCII('A') + ABS(CHECKSUM(NEWID()))%10) PRODUCTNAME
FROM SYS.OBJECTS A1
CROSS JOIN SYS.OBJECTS A2
CROSS JOIN SYS.OBJECTS A3
CROSS JOIN SYS.OBJECTS A4
CROSS JOIN SYS.OBJECTS A5
)
SELECT IDX, PRODUCTNAME, CAST(SUBSTRING(PRODUCTNAME,7,7) AS INT) PRODUCTID
, CAST(ABS(CHECKSUM(NEWID())) % 100 AS INT) SHOPID
, CAST(ABS(CHECKSUM(NEWID())) % 1000000 AS INT) PRICE
, DATEADD(MINUTE, CAST(ABS(CHECKSUM(NEWID())) % 20000 AS INT) * -1, GETDATE()) INSERTTIME
INTO TBLX
FROM TEMP
GO
--SELECT COUNT(*) FROM TBLX
--SELECT TOP 10 * FROM TBLX
CREATE UNIQUE CLUSTERED INDEX UCL_TBLX ON TBLX (IDX)
CREATE NONCLUSTERED INDEX NC_TBLX_02 ON TBLX (PRODUCTID)
GO
DBCC FREEPROCCACHE
GO
SET STATISTICS PROFILE ON
GO
-- SIMPLE PARAMETERIZATION을 방지하기 위해 JOIN 함
SELECT SUM(A.SHOPID)
FROM TBLX A
JOIN TBLX B
ON A.IDX = B.IDX
WHERE B.PRODUCTID < 0
-- SERIAL PLAN
SELECT SUM(A.SHOPID)
FROM TBLX A
JOIN TBLX B
ON A.IDX = B.IDX
WHERE B.PRODUCTID < 1000000
-- PARALLEL PLAN
SET STATISTICS PROFILE OFF
-- 이제 항상 PARALLEISM 으로 동작 시키기 위해서 PLAN 을 고정시켜 보고자 한다.
-- QUERY A START
DECLARE @STMT NVARCHAR(MAX);
DECLARE @PARAMS NVARCHAR(MAX);
EXEC SP_GET_QUERY_TEMPLATE N'
SELECT SUM(A.SHOPID)
FROM TBLX A
JOIN TBLX B
ON A.IDX = B.IDX
WHERE B.PRODUCTID < 1000000
',
@STMT OUTPUT,
@PARAMS OUTPUT;
-- 확인을 위한 쿼리
SELECT @STMT, @PARAMS
EXEC SP_CREATE_PLAN_GUIDE
@NAME = N'PLAN_GUIDE_TEST1',
@STMT = @STMT,
@TYPE = N'SQL',
@MODULE_OR_BATCH = NULL,
@PARAMS = @PARAMS,
@HINTS = N'OPTION (OPTIMIZE FOR (@0 = 1000000))'
-- QUERY A END
SELECT * FROM SYS.plan_guides WHERE NAME = 'PLAN_GUIDE_TEST1'
-- 이렇게 해서는 PLAN_GUIDE 가 동작하지 않는다.
-- 왜냐구? 파라미터된 계획과 그렇지 않는 계획은 다른것 이기 때문이다.
-- 아래 쿼리가 PARALLEL 로 돌아야 하는데 SERIAL 로 동작한다.
-- 속성에도 PLAN GUIDE 가 쓰지 않은 것으로 뜬다.
SELECT SUM(A.SHOPID)
FROM TBLX A
JOIN TBLX B
ON A.IDX = B.IDX
WHERE B.PRODUCTID < 1
-- SERIAL PLAN 으로 동작함
-- 옵셥 확인
SELECT CASE WHEN IS_PARAMETERIZATION_FORCED = 0 THEN 'DISABLED' ELSE 'ENABLED' END
, COMPATIBILITY_LEVEL
FROM SYS.DATABASES
WHERE NAME ='DB_PLAN_GUIDE_TEST'
GO
-- 강제 PARAMETERIZATION 활성화
ALTER DATABASE DB_PLAN_GUIDE_TEST SET PARAMETERIZATION FORCED
GO
-- 이제는 플랜가이드가 동작한다.
-- 기타 체크
-- 호환성 레벨 확인법
--exec sp_helpdb paging
--exec sp_dbcmptlevel paging
-- 호환성 레벨 변경방법
--ALTER DATABASE DB_PLAN_GUIDE_TEST
--SET COMPATIBILITY_LEVEL = 110
-- 호환성 레벨이 90 이상이고 IS_PARAMETERIZATION_FORCED 이 1 이면 가능하다.
DBCC FREEPROCCACHE
GO
SELECT SUM(A.SHOPID)
FROM TBLX A
JOIN TBLX B
ON A.IDX = B.IDX
WHERE B.PRODUCTID < 0
-- 병렬실행 계획이 동작한다면 정상이다.
-- 이 하나의 쿼리를 파라미터화 해서 쓰기 위해 전체 데이터베이스 옵션을 변경 할 수는 없다.
-- 그래서 다시 SIMPLE 로 돌린다.
ALTER DATABASE DB_PLAN_GUIDE_TEST SET PARAMETERIZATION SIMPLE
GO
DBCC FREEPROCCACHE
GO
-- 해당 쿼리만 PARAMETERIZATION FORCED 옵션을 만들어주는 플랜가이드를 하나 더 만든다.
-- 기발한 생각이죠?
DECLARE @STMT NVARCHAR(MAX);
DECLARE @PARAMS NVARCHAR(MAX);
EXEC SP_GET_QUERY_TEMPLATE N'
SELECT SUM(A.SHOPID)
FROM TBLX A
JOIN TBLX B
ON A.IDX = B.IDX
WHERE B.PRODUCTID < 1000000
',
@STMT OUTPUT,
@PARAMS OUTPUT;
EXEC sp_create_plan_guide
N'PLAN_GUIDE_TEST2',
@stmt,
N'TEMPLATE',
NULL,
@params,
N'OPTION(PARAMETERIZATION FORCED)';
GO
-- 아래와 같이 두개의 플랜가이드를 확인한다.
SELECT * FROM SYS.plan_guides
GO
plan_guide_id name create_date modify_date is_disabled query_text scope_type scope_type_desc scope_object_id scope_batch parameters hints
65537 PLAN_GUIDE_TEST1 2012-12-08 21:27:21.103 2012-12-08 21:27:21.103 0 select SUM ( A . SHOPID ) from TBLX A join TBLX B on A . IDX = B . IDX where B . PRODUCTID < @0 2 SQL NULL select SUM ( A . SHOPID ) from TBLX A join TBLX B on A . IDX = B . IDX where B . PRODUCTID < @0 @0 int OPTION (OPTIMIZE FOR (@0 = 1000000))
65539 PLAN_GUIDE_TEST2 2012-12-08 23:31:13.657 2012-12-08 23:31:13.657 0 select SUM ( A . SHOPID ) from TBLX A join TBLX B on A . IDX = B . IDX where B . PRODUCTID < @0 3 TEMPLATE NULL select SUM ( A . SHOPID ) from TBLX A join TBLX B on A . IDX = B . IDX where B . PRODUCTID < @0 @0 int OPTION(PARAMETERIZATION FORCED)
-- 결국 위 두개의 PLAN_GUIDE 조합으로 PARAMETERIZATION 이 SIMPLE 인데도 위 쿼리는 파라미터화 해서 동작 시킬 수 있다.
-- 아래 쿼리를 동작시키면 병렬로 동작 할 것이다.
SELECT SUM(A.SHOPID)
FROM TBLX A
JOIN TBLX B
ON A.IDX = B.IDX
WHERE B.PRODUCTID < 0
-- 일반적인 테스트 끝
-- 원상복귀
IF EXISTS (SELECT * FROM SYS.plan_guides WHERE NAME ='PLAN_GUIDE_TEST1')
EXEC SP_CONTROL_PLAN_GUIDE N'DROP', PLAN_GUIDE_TEST1
GO
IF EXISTS (SELECT * FROM SYS.plan_guides WHERE NAME ='PLAN_GUIDE_TEST2')
EXEC SP_CONTROL_PLAN_GUIDE N'DROP', PLAN_GUIDE_TEST2
GO
IF EXISTS (SELECT * FROM SYS.plan_guides WHERE NAME ='PLAN_GUIDE_TEST3')
EXEC SP_CONTROL_PLAN_GUIDE N'DROP', PLAN_GUIDE_TEST3
GO
-- 동작의 검증
--PROFILER 에서 PERFORMANCE > PLAN GUIDE SUCCESSFUL , PLAN GUIDE UNSUCCESSFUL 로 확인 가능하다.
--GRAPHIC 실행계획의 마지막 이터레이터에서 속성을 확인하면 플랜가이드가 사용된 것을 확인 할 수 있다.
-- 테스트 시나리오 2
-- 아래는 SP_CREATE_PLAN_GUIDE_FROM_HANDLE 으로 플랜을 고정시키는 방법이다.
-- 플랜에 올라온 실행계획을 고정시키는 방법이다.
-- 그러나, 이 방법으로 MEMORY GRANT 는 고정시킬 수 없고, 역시 PARAMETERIZATION FORCE 는 개별로 ENABLE 시키던지
-- 데이터베이스 전역으로 ENABLE 시켜야 한다.
-- 그러므로 OPTIMIZER FOR 를 이용해 실행시 PARAMETER 를 인식시켜 충분한 메모리를 할당 받을 수
-- 있도록 하는것이 최선의 방법이다.
-- 어떤 방법이든, 방법의 한계를 잘 이해하는 것이 중요하다.
-- 역시 SIMPLE인 상태에서 파라미터화 해서 쓰기위해서 다음 플랜가이드를 먼저 만든다.
DECLARE @STMT NVARCHAR(MAX);
DECLARE @PARAMS NVARCHAR(MAX);
EXEC SP_GET_QUERY_TEMPLATE N'
SELECT SUM(A.SHOPID)
FROM TBLX A
JOIN TBLX B
ON A.IDX = B.IDX
WHERE B.PRODUCTID < 1000000
',
@STMT OUTPUT,
@PARAMS OUTPUT;
EXEC sp_create_plan_guide
N'PLAN_GUIDE_TEST2',
@stmt,
N'TEMPLATE',
NULL,
@params,
N'OPTION(PARAMETERIZATION FORCED)';
GO
DBCC FREEPROCCACHE
GO
-- 병렬쿼리로 동작 할꺼다.
SELECT SUM(A.SHOPID)
FROM TBLX A
JOIN TBLX B
ON A.IDX = B.IDX
WHERE B.PRODUCTID < 10000000
GO
-- 이 플랜을 받아서 고정시켜보자
-- 그런데 이번에는 좀 스마트하게 SP_CREATE_PLAN_GUIDE_FROM_HANDLE 에서 받아볼까?
DECLARE @PLAN_HANDLE VARBINARY(1000)
SELECT @PLAN_HANDLE = PLAN_HANDLE
--SELECT *
FROM SYS.DM_EXEC_QUERY_STATS QS
CROSS APPLY SYS.DM_EXEC_SQL_TEXT(QS.SQL_HANDLE) SQT
WHERE TEXT LIKE '%SUM%SHOPID%PRODUCTID%'
AND TEXT NOT LIKE '%SYS.DM_EXEC%'
SELECT @PLAN_HANDLE
EXEC SP_CREATE_PLAN_GUIDE_FROM_HANDLE 'PLAN_GUIDE_TEST3', @PLAN_HANDLE=@PLAN_HANDLE
GO
DBCC FREEPROCCACHE
GO
SELECT SUM(A.SHOPID)
FROM TBLX A
JOIN TBLX B
ON A.IDX = B.IDX
WHERE B.PRODUCTID < 0
GO
--MemoryGrant="25736"
DBCC FREEPROCCACHE
GO
SELECT SUM(A.SHOPID)
FROM TBLX A
JOIN TBLX B
ON A.IDX = B.IDX
WHERE B.PRODUCTID < 10000000
GO
--MemoryGrant="205960"
-- 위와 같이 플랜은 같게 플랜 가이드를 잘 쓰지만 메모리 GRANT 는 크게 차이가 나고 처음에 0을 넣고
-- 돌린 쿼리가 돌게되면 두번째 쿼리 변수가 크면 이번에는 HASH WARNING 이 발생하면서 TEMPDB SPILL 이 발생한다.
-- 동작 속도도 엄청나게 떨어지게 된다.
-- 테스트를 완료 했으면, 플랜 가이드를 지운다.
IF EXISTS (SELECT * FROM SYS.plan_guides WHERE NAME ='PLAN_GUIDE_TEST1')
EXEC SP_CONTROL_PLAN_GUIDE N'DROP', PLAN_GUIDE_TEST1
GO
IF EXISTS (SELECT * FROM SYS.plan_guides WHERE NAME ='PLAN_GUIDE_TEST2')
EXEC SP_CONTROL_PLAN_GUIDE N'DROP', PLAN_GUIDE_TEST2
GO
IF EXISTS (SELECT * FROM SYS.plan_guides WHERE NAME ='PLAN_GUIDE_TEST3')
EXEC SP_CONTROL_PLAN_GUIDE N'DROP', PLAN_GUIDE_TEST3
GO
-- 2번 테스트 끝
-- 강제 파라미터화를 위해 PLAN_GUIDE_TEST2 는 지우지 않았다.
-- 테이블 힌트를 통해서 플랜가이드를 주었을때 해당 인덱스가 삭제되면
-- 어떻게 될까? (동작하지 않는다.)
-- CREATE NONCLUSTERED INDEX NC_TBLX_02 ON TBLX (PRODUCTID)
GO
DECLARE @STMT NVARCHAR(MAX);
DECLARE @PARAMS NVARCHAR(MAX);
EXEC SP_GET_QUERY_TEMPLATE N'
SELECT SUM(A.SHOPID)
FROM TBLX A
JOIN TBLX B
ON A.IDX = B.IDX
WHERE B.PRODUCTID < 1000000
',
@STMT OUTPUT,
@PARAMS OUTPUT;
EXEC sp_create_plan_guide
N'PLAN_GUIDE_TEST2',
@stmt,
N'TEMPLATE',
NULL,
@params,
N'OPTION(PARAMETERIZATION FORCED)';
GO
DECLARE @STMT NVARCHAR(MAX);
DECLARE @PARAMS NVARCHAR(MAX);
EXEC SP_GET_QUERY_TEMPLATE N'
SELECT SUM(A.SHOPID)
FROM TBLX A
JOIN TBLX B
ON A.IDX = B.IDX
WHERE B.PRODUCTID < 1000000
',
@STMT OUTPUT,
@PARAMS OUTPUT;
-- 확인을 위한 쿼리
SELECT @STMT, @PARAMS
EXEC SP_CREATE_PLAN_GUIDE
@NAME = N'PLAN_GUIDE_TEST1',
@STMT = @STMT,
@TYPE = N'SQL',
@MODULE_OR_BATCH = NULL,
@PARAMS = @PARAMS,
@HINTS = N'OPTION (TABLE HINT (B, INDEX(NC_TBLX_02)))'
-- QUERY A END
-- 인덱스 힌트를 주고 해당 인덱스를 삭제할 경우
-- 플랜 가이드에 명시적으로 TABLE HINT 로 인덱스가 명시되어 있는데 없어지면 실행이 되지 않는다.
DROP INDEX TBLX.NC_TBLX_02
GO
DBCC FREEPROCCACHE
GO
SELECT SUM(A.SHOPID)
FROM TBLX A
JOIN TBLX B
ON A.IDX = B.IDX
WHERE B.PRODUCTID < 1000000
GO
-- 동작하지 않는다.
SELECT *
FROM SYS.PLAN_GUIDES A
CROSS APPLY SYS.FN_VALIDATE_PLAN_GUIDE (A.PLAN_GUIDE_ID)
GO
-- 인덱스 만들면 잘 동작한다.
CREATE NONCLUSTERED INDEX NC_TBLX_02 ON TBLX (PRODUCTID)
GO
-- Index 'NC_TBLX_02' on table 'TBLX' (specified in the FROM clause) does not exist.
-- 라고 기록되며 실행되지 않는다.
-- 동일한 인덱스 이름을 만들어 주면 잘 동작한다.
-- 오류가 생기는 시점은 인덱스가 삭제되면 바로 발생한다.
-- 해당 테스트는 JOIN TBLX B WITH(INDEX(NC_TBLX_02)) 로 힌트를 주더라도 같다.
-- USE PLAN 에서 사용된 인덱스가 없어져도 무시하고 실행되는 경우는
-- 명시적 인덱스 힌트를 사용하지 않고 만들어진 쿼리플랜을 USE PLAN 으로 사용할 때
-- 인덱스를 지우면 FN_VALIDATE_PLAN_GUIDE 에 오류가 남고 실행은 된다.
-- 실행은 되나 플랜의 최 하단 이터레이터에서 속성을 확인하면, 플랜 가이드를 쓰지 않은것을 볼 수 있다.
-- 다른 테스트를 위해 플랜 가이드 제거
EXEC SP_CONTROL_PLAN_GUIDE N'DROP', PLAN_GUIDE_TEST1
GO
EXEC SP_CONTROL_PLAN_GUIDE N'DROP', PLAN_GUIDE_TEST2
GO
EXEC SP_CONTROL_PLAN_GUIDE N'DROP', PLAN_GUIDE_TEST3
GO
DBCC FREEPROCCACHE
GO
--DROP INDEX TBLX.NC_TBLX_02
--GO
DECLARE @STMT NVARCHAR(MAX);
DECLARE @PARAMS NVARCHAR(MAX);
EXEC SP_GET_QUERY_TEMPLATE N'
SELECT SUM(A.SHOPID)
FROM TBLX A
JOIN TBLX B
ON A.IDX = B.IDX
WHERE B.PRODUCTID < 1000000
',
@STMT OUTPUT,
@PARAMS OUTPUT;
EXEC sp_create_plan_guide
N'PLAN_GUIDE_TEST2',
@stmt,
N'TEMPLATE',
NULL,
@params,
N'OPTION(PARAMETERIZATION FORCED)';
GO
CREATE NONCLUSTERED INDEX NC_TBLX_02 ON TBLX (PRODUCTID)
GO
-- 아래 쿼리는 TBLX NC_TBLX_02 를 쓰는 실행계획이다.
-- 플랜 확인 할 것
SELECT SUM(A.SHOPID)
FROM TBLX A
JOIN TBLX B
ON A.IDX = B.IDX
WHERE B.PRODUCTID < 1000000
GO
-- USE PLAN 을 이용해 PLAN GUIDE 생성하기
-- QUERY B START
DECLARE @SQL_XML_PLAN NVARCHAR(MAX)
DECLARE @STMT NVARCHAR(MAX);
DECLARE @PARAMS NVARCHAR(MAX);
SELECT @SQL_XML_PLAN =
CONVERT(NVARCHAR(MAX),SQP.QUERY_PLAN)
FROM SYS.DM_EXEC_QUERY_STATS QS
CROSS APPLY SYS.DM_EXEC_SQL_TEXT(QS.SQL_HANDLE) SQT
CROSS APPLY SYS.DM_EXEC_QUERY_PLAN(QS.PLAN_HANDLE) SQP
WHERE TEXT LIKE '%SUM%SHOPID%PRODUCTID%'
AND TEXT NOT LIKE '%SYS.DM_EXEC%'
EXEC SP_GET_QUERY_TEMPLATE N'
SELECT SUM(A.SHOPID)
FROM TBLX A
JOIN TBLX B
ON A.IDX = B.IDX
WHERE B.PRODUCTID < 1000000
',
@STMT OUTPUT,
@PARAMS OUTPUT;
-- 확인을 위한 쿼리
SELECT @STMT, @PARAMS
SELECT @SQL_XML_PLAN
SET @SQL_XML_PLAN = 'OPTION(USE PLAN '''+@SQL_XML_PLAN+''')'
EXEC SP_CREATE_PLAN_GUIDE @NAME =N'PLAN_GUIDE_TEST3'
, @STMT = @STMT
, @TYPE = N'SQL'
, @MODULE_OR_BATCH = NULL
, @PARAMS = @PARAMS
, @HINTS = @SQL_XML_PLAN
-- QUERY B END
DROP INDEX TBLX.NC_TBLX_02
GO
-- 플랜 가이드를 무시하고, 클러스터 인덱스를 이용해 잘 실행한다.
SELECT SUM(A.SHOPID)
FROM TBLX A
JOIN TBLX B
ON A.IDX = B.IDX
WHERE B.PRODUCTID < 0
-- 인덱스 삭제등의 문제가 있으면 아래 쿼리로 확인 가능하다.
SELECT *
FROM SYS.PLAN_GUIDES A
CROSS APPLY SYS.FN_VALIDATE_PLAN_GUIDE (A.PLAN_GUIDE_ID)
GO
-- 인덱스 만들어주면 다시 잘 동작한다.
CREATE NONCLUSTERED INDEX NC_TBLX_02 ON TBLX (PRODUCTID)
GO
-- 이번에는 플랜가이드를 사용할 것이다.
SELECT SUM(A.SHOPID)
FROM TBLX A
JOIN TBLX B
ON A.IDX = B.IDX
WHERE B.PRODUCTID < 0
--Index 'DB_PLAN_GUIDE_TEST.dbo.TBLX.NC_TBLX_02', specified in the USE PLAN hint, does not exist. Specify an existing index, or create an index with the specified name.
-- 플랜가이드 제거
IF EXISTS (SELECT * FROM SYS.plan_guides WHERE NAME ='PLAN_GUIDE_TEST1')
EXEC SP_CONTROL_PLAN_GUIDE N'DROP', PLAN_GUIDE_TEST1
GO
IF EXISTS (SELECT * FROM SYS.plan_guides WHERE NAME ='PLAN_GUIDE_TEST2')
EXEC SP_CONTROL_PLAN_GUIDE N'DROP', PLAN_GUIDE_TEST2
GO
IF EXISTS (SELECT * FROM SYS.plan_guides WHERE NAME ='PLAN_GUIDE_TEST3')
EXEC SP_CONTROL_PLAN_GUIDE N'DROP', PLAN_GUIDE_TEST3
GO
-- 원본 쿼리의 힌트제거 방법
-- 아래와 같이 ISV 개발자가 임으로 HASH JOIN 을 기술해 개발해 놓았으나
-- 내 데이터베이스에서는 해당 힌트가 동작하지 않았으면 한다. (무시하길 원한다.)
-- 단, 아래 방법은 FROM 절에 JOIN 힌트로 기술되어 있거나, 다른 JOIN 방법을 명시하는 것은 불가능 하다.
SELECT SUM(A.SHOPID)
FROM TBLX A
JOIN TBLX B
ON A.IDX = B.IDX
WHERE B.PRODUCTID < 0
OPTION (HASH JOIN)
-- 1. SIMPLE PARAMETERIZATION 데이터베이스에서 테스트 하기 위해 개별 쿼리에
-- PARAMETERIZATION 을 활성화 한다.
DECLARE @STMT NVARCHAR(MAX);
DECLARE @PARAMS NVARCHAR(MAX);
EXEC SP_GET_QUERY_TEMPLATE N'
SELECT SUM(A.SHOPID)
FROM TBLX A
JOIN TBLX B
ON A.IDX = B.IDX
WHERE B.PRODUCTID < 0
OPTION (HASH JOIN)
',
@STMT OUTPUT,
@PARAMS OUTPUT;
EXEC sp_create_plan_guide
N'PLAN_GUIDE_TEST2',
@stmt,
N'TEMPLATE',
NULL,
@params,
N'OPTION(PARAMETERIZATION FORCED)';
GO
-- 2. HINT 절에 NULL 을 기술해 힌트를 제거한다.
DECLARE @STMT NVARCHAR(MAX);
DECLARE @PARAMS NVARCHAR(MAX);
EXEC SP_GET_QUERY_TEMPLATE N'
SELECT SUM(A.SHOPID)
FROM TBLX A
JOIN TBLX B
ON A.IDX = B.IDX
WHERE B.PRODUCTID < 0
OPTION (HASH JOIN)
',
@STMT OUTPUT,
@PARAMS OUTPUT;
-- 확인을 위한 쿼리
SELECT @STMT, @PARAMS
EXEC SP_CREATE_PLAN_GUIDE
@NAME = N'PLAN_GUIDE_TEST1',
@STMT = @STMT,
@TYPE = N'SQL',
@MODULE_OR_BATCH = NULL,
@PARAMS = @PARAMS,
@HINTS = NULL
-- QUERY A END
GO
DBCC FREEPROCCACHE
GO
SELECT SUM(A.SHOPID)
FROM TBLX A
JOIN TBLX B
ON A.IDX = B.IDX
WHERE B.PRODUCTID < 0
OPTION (HASH JOIN)
-- 플랜가이드 제거
IF EXISTS (SELECT * FROM SYS.plan_guides WHERE NAME ='PLAN_GUIDE_TEST1')
EXEC SP_CONTROL_PLAN_GUIDE N'DROP', PLAN_GUIDE_TEST1
GO
IF EXISTS (SELECT * FROM SYS.plan_guides WHERE NAME ='PLAN_GUIDE_TEST2')
EXEC SP_CONTROL_PLAN_GUIDE N'DROP', PLAN_GUIDE_TEST2
GO
IF EXISTS (SELECT * FROM SYS.plan_guides WHERE NAME ='PLAN_GUIDE_TEST3')
EXEC SP_CONTROL_PLAN_GUIDE N'DROP', PLAN_GUIDE_TEST3
GO
http://msdn.microsoft.com/en-us/library/ms191275(v=sql.100).aspx
http://msdn.microsoft.com/en-us/library/ms190417(v=sql.100).aspx
 bootimg.zip
bootimg.zip


 XArp_1.5.exe
XArp_1.5.exe

 plan_guide_test.sql
plan_guide_test.sql